Message boards : Theory Application : Windows Version
Message board moderation
Previous · 1 · 2 · 3 · 4 · 5 · 6 · Next
| Author | Message |
|---|---|
 Ray Murray Ray MurraySend message Joined: 13 Apr 15 Posts: 138 Credit: 3,015,630 RAC: 0 |
Just repeated this to make sure I hadn't mistaken it yesterday with the reversion to 4.16. Checked all 3 hosts have 2019_02_20 vdi. On requesting new work, if there is already a task running, only the .run file is downloaded. (all good). However, if the host has been allowed to run dry, even though the vdi is already in the dev project folder, it downloads the 421MB vdi again. Not good for those on limited or slow connections. |
|
Send message Joined: 13 Feb 15 Posts: 1281 Credit: 1,048,477 RAC: 54 |
.... it downloads the 421MB vdi again. Not good for those on limited or slow connections.A fresh load of all project files after a 'reset project' may help. For safety backup the evt. app_config.xml. |
|
Ray Murray Send message Joined: 13 Apr 15 Posts: 138 Credit: 3,015,630 RAC: 0 |
I would try that if this was only happening on just 1 host but I find this to be repeatable over all 3 of my hosts. It's not really a problem for me as I have a reasonably fast, unlimited connection but it might be interesting to see if anyone else could reproduce the behaviour. |
|
Ray Murray Send message Joined: 13 Apr 15 Posts: 138 Credit: 3,015,630 RAC: 0 |
I only let my machines grab a couple of these at a time, supposedly so that I can watch for irregularities, although I normally get distracted and miss whatever I was hoping to spot. On further inspection of the previous behaviour, I find that the vdi is deleted when the last task finishes, hence the new download with each new batch of work requested. Only its .xml is retained. I had earlier mistaken the deprecated 2019_02_22, which I have now deleted. Too late at night to investigate further tonight so I'll have another look tomorrow evening, with CP's reset suggestion as first option. |
|
Magic Quantum Mechanic Send message Joined: 8 Apr 15 Posts: 1018 Credit: 18,546,558 RAC: 20,072 |
Theory Simulation v4.16 (vbox64_mt_mcore) windows_x86_64 lhcathome-dev | setup_file: projects/lhcathomedev.cern.ch_lhcathome-dev/Theory_2019_02_20.vdi (input) Seems to be working so far and the ones I watched before that didn't get this far would *cranky: [ERROR] Container 'runc' failed.* 00:01:40.137322 VMMDev: Guest Log: 23:46:52 2019-02-27: cranky: [INFO] Detected Theory App 00:01:40.154865 VMMDev: Guest Log: 23:46:52 2019-02-27: cranky: [INFO] Checking CVMFS. 00:01:52.022449 VMMDev: Guest Log: 23:47:03 2019-02-27: cranky: [INFO] Checking runc. 00:01:52.094419 VMMDev: Guest Log: 23:47:04 2019-02-27: cranky: [INFO] Creating the filesystem. 00:01:52.116827 VMMDev: Guest Log: 23:47:04 2019-02-27: cranky: [INFO] Using /cvmfs/cernvm-prod.cern.ch/cvm3 00:01:52.427319 VMMDev: Guest Log: 23:47:04 2019-02-27: cranky: [INFO] Updating config.json. 00:01:52.539871 VMMDev: Guest Log: 23:47:04 2019-02-27: cranky: [INFO] Running Container 'runc'.  Just passed 6500 events |
|
Send message Joined: 28 Jul 16 Posts: 544 Credit: 400,710 RAC: 0 |
... I find that the vdi is deleted when the last task finishes, ... I remember the same issue appeared a long while ago at lhc-production. The reason was an error in the server templates. Thus it has to be solved there. |
|
Magic Quantum Mechanic Send message Joined: 8 Apr 15 Posts: 1018 Credit: 18,546,558 RAC: 20,072 |
https://lhcathomedev.cern.ch/lhcathome-dev/result.php?resultid=2755778 Run 9 hours Valid (over 100K events) |
|
Send message Joined: 13 Feb 15 Posts: 1281 Credit: 1,048,477 RAC: 54 |
https://lhcathomedev.cern.ch/lhcathome-dev/result.php?resultid=2755778 MAGIC, you was lucky. During the reporting and cleanup phase the Task was restarted: 2019-02-28 00:42:15 (8184): Guest Log: 08:42:15 2019-02-28: cranky: [INFO] Preparing output. 2019-02-28 00:42:16 (8184): VM Completion File Detected. 2019-02-28 00:42:16 (8184): Powering off VM. 2019-02-28 00:50:57 (6044): Detected: vboxwrapper 26197 2019-02-28 00:50:57 (6044): Detected: BOINC client v7.7 2019-02-28 00:50:59 (6044): Detected: VirtualBox VboxManage Interface (Version: 5.2.16) 2019-02-28 00:51:00 (6044): Starting VM using VBoxManage interface. (boinc_1c3c27b5413106a8, slot#1) 2019-02-28 00:51:06 (6044): Successfully started VM. (PID = '7376') Conclusion: VBoxwrapper is quite stable. |
|
Magic Quantum Mechanic Send message Joined: 8 Apr 15 Posts: 1018 Credit: 18,546,558 RAC: 20,072 |
Yes I actually did that on purpose just to see what it would do and was glad to see it still finish and report just to see if it would still upload before I start a new one. Then after it was reported I had to go back to the VB Manager to *remove* that *saved* I actually had that VM Console running in front of me and watched it run and saved some other things since I was running this task as 2-core and at the same time 3 other LHC Theory 2-core tasks and a couple times saw a Pythia warning and checking the task manager and saw it had the CPU running at 100% so I decided to suspend one of those LHC tasks to free up 2 cores just hoping I didn't have a task running for over 3 hours crash on me. I took the snapshots but that was on the host sitting next to this one so maybe later I will post that (its 3am now) But I agree that it does seem that the wrapper is quite stable and will run another one to see if it works again. |
|
Magic Quantum Mechanic Send message Joined: 8 Apr 15 Posts: 1018 Credit: 18,546,558 RAC: 20,072 |
https://lhcathomedev.cern.ch/lhcathome-dev/result.php?resultid=2755779 This one didn't survive but it is a typical thing that happens with these VB tasks anyway so I did expect it to happen. (I suspended the task with a 12 minute run time and for my ISP it tends to take longer for them to start a slot- job so as I expected the VB crashed seconds after this restart) CPU time was only 2 min 44 sec.......no big deal and the main thing is VB tasks do not like to be suspended until after starting a sub task in the slot. That last one that did work was after running events for 9 hours and I suspended it at the end and tried to see if a reboot would cause a problem and it didn't and still uploaded after I messed around with the VB manager restart......so yes the wrapper is fine and I will now start a new one and just let it run from start to finish. (and while I'm here I will add those snapshots of one of the 2 Pythia warnings that happened and why I took a wild guess and just suspended another 2-core LHC task to free up the CPU and after that it ran the next 6 hours without any warnings) 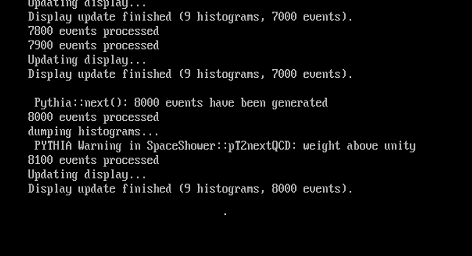 while running the CPU's at 100% 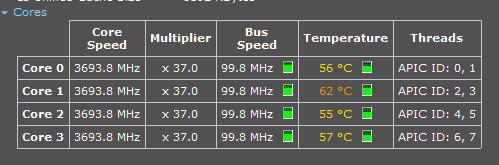 So I will run another 2-core task and leave a LHC task suspended just to watch the Console as it runs and with the task manager to watch that run with the free core. |
|
Magic Quantum Mechanic Send message Joined: 8 Apr 15 Posts: 1018 Credit: 18,546,558 RAC: 20,072 |
Grrrrrrrrrrrrrr https://lhcathomedev.cern.ch/lhcathome-dev/result.php?resultid=2757020 and I got to see it happen.......18 hours of wasted time. |
|
Send message Joined: 13 Feb 15 Posts: 1281 Credit: 1,048,477 RAC: 54 |
I've now running a job without proceeding output to the Console. This is what I see:  It's using 115% of 1 core and the job it should run from the input file is [boinc pp zinclusive 7000 20,-,50,200 - madgraph5amc 2.6.2.atlas default 100000 26] Meanwhile the task finished and returned with an unknown error code https://lhcathomedev.cern.ch/lhcathome-dev/result.php?resultid=2757345 2019-03-05 08:00:09 (2876): Guest Log: 07:00:09 2019-03-05: cranky: [INFO] Running Container 'runc'. 2019-03-05 08:50:47 (2876): Guest Log: 07:50:02 2019-03-05: cranky: [ERROR] Container 'runc' failed. |
|
Send message Joined: 13 Feb 15 Posts: 1281 Credit: 1,048,477 RAC: 54 |
I fetched a screenshot during the job-initializing phase and saw a part of a job log file in between.  It should be job [boinc pp zinclusive 7000 20,-,50,200 - pythia6 6.426 359 100000 28] according to the input file, but I cannot verify that's the job running cause the output is frozen. As reported before the same output is shown again after the job is setup and nothing more and using more than 100% of 1 core. It looks like the image in the previous post. I have no confidence in this task so will kill it. |
|
Ray Murray Send message Joined: 13 Apr 15 Posts: 138 Credit: 3,015,630 RAC: 0 |
I've had a few of these, too, with the exact same screen output as CP's earlier screenshot. They tend to "run" for 1 - 2hrs, using ALL of a core for that time then exit with an "unknown error code", (incorrect function in stderr) Resetting the VM doesn't help as it always gets stuck at the same place. Latest one, here, will "finish" about 20:00ish UTC so I'm just going to let it run in case it shows up anything interesting in the upload. Don't know where else to look for any other pointers. |
|
Ray Murray Send message Joined: 13 Apr 15 Posts: 138 Credit: 3,015,630 RAC: 0 |
https://lhcathomedev.cern.ch/lhcathome-dev/result.php?resultid=2769602 and https://lhcathomedev.cern.ch/lhcathome-dev/result.php?resultid=2769692 ran for more than 19hrs each but threw -240, upload failure: <file_xfer_error>, presumably because a job was still running when the time limit kicked in so there was no completion file to upload. With "ordinary" VMs that Job would simply be lost but the Task would still be credited. |
|
Ray Murray Send message Joined: 13 Apr 15 Posts: 138 Credit: 3,015,630 RAC: 0 |
At the rate the console is whizzing by, I suspect this one would have been an Exceeded-disk-limit failure had it been in a Production VM but as don't know where the corresponding logs are kept in the VM here, I can't tell for sure so I'm letting it run for now but I'm not hopeful for its outcome. echo "runspec=boinc pp jets 7000 170,-,2960 - sherpa 2.1.1 default 38000 46" echo "run=pp jets 7000 170,-,2960 - sherpa 2.1.1 default" echo "jobid=49639792" echo "revision=2279" echo "runid=772896" I'm also getting 10 or more a day, across my 3 machines, of the c.2hr Unknown Error / Incorrect Function failures as previously detailed by CP. |
|
Magic Quantum Mechanic Send message Joined: 8 Apr 15 Posts: 1018 Credit: 18,546,558 RAC: 20,072 |
cranky: [ERROR] 'cvmfs_config probe alice.cern.ch' failed First time I have seen this happen ( 2 of the 2-core version Theory Simulation v4.16 ) https://lhcathomedev.cern.ch/lhcathome-dev/result.php?resultid=2770802 I guess I will try a new d/l of this vdi and see if it works (probably take 6 hours) |
|
Send message Joined: 29 Apr 19 Posts: 13 Credit: 109,352 RAC: 0 |
Started my first Theory work here. BOINC 7.14.1 Virtual Box 5.1.26 r117224 Preferences were set to 4 cores and the 1st WU completed in 2000 seconds CPU time ~ 2300 s. 2nd work unit https://lhcathomedev.cern.ch/lhcathome-dev/result.php?resultid=2772209 ran while I slept and went for 9+ hours. The console had a request to make a bug report to GNU. I suspended it and then created an app_config.xml to run Theory at 1 core w/ default RAM 1030mb to avoid so much idle CPU time (guess that's not changed on this test version). The broken WU with the request for bug report to GNU, what next for it? |
|
Ray Murray Send message Joined: 13 Apr 15 Posts: 138 Credit: 3,015,630 RAC: 0 |
Is there any way to "end gracefully" faulty jobs such as CP's screenshot (of which I seem to get quite a lot) or ones that are clearly going to Exceed disk limit (not so many), like one can with standard production VMs by editing the checkpoint to fool it into thinking it has run to term? I've tried that here and it doesn't work. Is the only option to Abort said tasks or let them error out on their own? |
|
Ray Murray Send message Joined: 13 Apr 15 Posts: 138 Credit: 3,015,630 RAC: 0 |
Still getting 3 or 4 a day of the "busy doing nothing" ones (per CP's screenshots) that seem to get stuck between setting up and processing then spend c.2hrs apparently doing nothing, but using a whole core to do that nothing, before ending in error for no credits. I have been Aborting any of these that I catch but have been wondering if there is anything returned that might isolate WHY they do this? If they return something useful, I will let them run but if not, I will continue to Abort them. I have extended the time limit to allow healthy-looking, long runners a chance to complete but I would be interested to learn if anyone has found a way to "gracefully end" loopers or those that will clearly end in disk-limit errors so that at least some credits are awarded for the time, rather than none at all. (repeating from my last post but I don't know how to do it myself, or if it is even possible since there now appears to be less reliance on writing stuff to/from Boinc, out-with the VM itself.) |

©2026 CERN