Message boards : CMS Application : New version 49.00
Message board moderation
Previous · 1 · 2 · 3 · 4 · 5 · 6 · Next
| Author | Message |
|---|---|
 Magic Quantum Mechanic Magic Quantum MechanicSend message Joined: 8 Apr 15 Posts: 1019 Credit: 18,565,973 RAC: 20,586 |
I agree with you Stefan And the reason I bring this up (many times in the past) is because of how this would work with members new or old over at LHC since then we would get many who get this problem and then hundreds of threads and posts from not very happy crunchers. I first brought this up several years ago when testing Atlas alpha versions It is one thing to download these tasks (and vdi's) but it is another thing when you have all of that loaded and ready BUT still have to depend on a fast enough connection and back and forth communication with the Cern server just to get a task to get past the HTCondor ping and then the epl/primary_db and sl-security/primary_db that can be painfully slow to watch running and finally finished just to get to the start of the jobs/slots As you may remember I have Hughes satellite as my isp (both directions) so I am not sure how many people run off the same server in my area but I know there can't be many people using this after midnight other than myself and I can test my speed and it will be what you would think is fast enough (1-3Gbps) yet the connection with Cern will be much slower than that every time........even just loading the LHC websites and logging in is slower than you would expect........and since I have 10 computers running and no firewall or security programs slowing it down it has to be a problem between my first Hughes server and Cern And I imagine the average person on a dsl or cable that tries to do this from 5,000 miles away could have the same problems This also has me wanting to see just how many times this signal has to go from my Dish to the satellite and back to Earth and back up to get to Geneva (I am about 5,200 miles away) Ok I am hoping to get 2 of the 2-core tasks to start tonight and it is after 3am and I have to get up in a few hours to take the wife to some hospital tests so I will hope those tasks actually start running the jobs........yeah I have a laptop next to my bed.........over the hill mad scientist   |
|
Magic Quantum Mechanic Send message Joined: 8 Apr 15 Posts: 1019 Credit: 18,565,973 RAC: 20,586 |
https://lhcathomedev.cern.ch/lhcathome-dev/result.php?resultid=2772647 Oy Vey 5hrs 20mins before [ERROR] Condor ended after 17297 seconds Lost both tasks I tried to run earlier in the day and now after midnight lets see if I can get two of these 2-core tasks to complete Valid. |
|
Send message Joined: 29 Apr 19 Posts: 13 Credit: 109,352 RAC: 0 |
Every task is ending in "1 (0x00000001) Unknown error code". The machine is staying just under commits that would put it into the swap file. Virtual Box v 5.1.28, Windows 8.1. This machine just ran the Theory WU's successfully. It's running 1x TACC boinc2dockers (successfully) while running 1x CMS jobs. Running 7 other custom VM's. Logs: 2019-05-03 03:15:47 (3848): Guest Log: [ERROR] Condor ended after 784 seconds. 2019-05-03 03:15:47 (3848): Guest Log: [INFO] Shutting Down. -------------------------------------------------------------------------- Shutdown all VM's, killed VBox service and restarted VBox. Started a fresh CMS VM and watched the startup. Things that are out of ordinary as starting: can't rename eth0 -> eth1. Resource maybe busy. ip6tables: no config file Warning ip4tables: no config file Warning You may need to restart the Windows system or restart the guest system to enable Guest Additions. (machine was restarted earlier in the day during the lightning storm) Starting vmcontext_hepix Warning - - . HT Condor Ping Watching with Process Hacker: disk writes ~ 2-4kb/s, network transfers ~ 0.05 -> 4kb/s. Certainly taking a very long time to get it's work. Start d/ls at 5:40am, ended by 6:00 am. ERROR: Condor ended after 787 seconds. ------------------ So it appears my issue is similar to other people. The VM gives up after failing to get the data set before timing out due to slow connection to CONDOR. This issue is at the server or the VM needs to be more lenient on the time outs before failing the job. All the other work in the home is d/led and forget; no continuous connections to CONDOR or other outside servers. (Except maybe 1x boinc2docker, not sure). Not even streaming a movie while CMS was running. Fast.com reports full 20MB/s connection available. Last year, without a local proxy, this ISP allowed me to run 90 Theory at once all connected to CONDOR. It's not like a lot of dev CMS are currently even running at this time. Is there something wrong with the configuration of the guest VM's ethernet connection? |
|
Send message Joined: 29 Apr 19 Posts: 13 Credit: 109,352 RAC: 0 |
Indeed a very poor download rate. Good idea. Great catch on your part, especially if it solves this issue. You deserve appreciation and a name mention pushed down to all the BOINC Mgr clients attributing the solution to your ingenuity. 2. Volunteers could configure their local firewall to reject connections to slow mirror servers. Not great ideas. We're unpaid volunteers with jobs and families. It's hard enough to get masses of people, volunteering to work on BOINC science projects, to write their own app_config.xml let alone manually adjust firewall settings or setup a local proxy servers. The very first sentence at the BOINC homepage sets the guiding philosophy for all BOINC projects: BOINC lets you help cutting-edge science research using your computer (Windows, Mac, Linux) or Android device. BOINC downloads scientific computing jobs to your computer and runs them invisibly in the background. It's easy and safe. - https://boinc.berkeley.edu/ it's EASY and safe. Not, you'll need to setup your on squid proxy, manually adjust your firewall settings, build your own custom VM to run native WU's or leave behind the common OS installed on your Best Buy tablet/phone/laptop and install a special OS. The project developers want large numbers of people to volunteer to work on their project; then make it easy to do so. Don't push work onto the volunteers when a solution exists that a paid employee can easily solve. Follow the guiding philosophy of BOINC: It's easy and safe to volunteer to do science. |
|
Send message Joined: 28 Jul 16 Posts: 544 Credit: 400,710 RAC: 0 |
Did you check your firewall? CMS needs additional ports. See: http://lhcathome.web.cern.ch/test4theory/my-firewall-complaining-which-ports-does-project-use Beside that: You mentioned a couple of errors before the successful HTCondor ping. All of them can be ignored. Suggestion: If you suspect your internet connection could be too slow, you may try to get at first a singlecore setup running. Your recent 4-core-setup may try too many downloads concurrently. (I personally don't think this is the reason) |
|
Send message Joined: 29 Apr 19 Posts: 13 Credit: 109,352 RAC: 0 |
Did you check your firewall? That's possible given that Windows firewall came up and asked for permissions about 10:45UTC, which I allowed on private networks (inside the home to my router). The previous failed 50 WU's were while I was asleep and not around to answer firewall notifications. But, It's failed 2 more CMS since I accepted the Firewall permissions. https://lhcathomedev.cern.ch/lhcathome-dev/result.php?resultid=2772620 https://lhcathomedev.cern.ch/lhcathome-dev/result.php?resultid=2772865 For diagnostics, shutting the machine's local firewall off for the few hours and see if any of the 4 core CMS in the queue survive. If this fixes it then I'll comb through the rules looking for the blocking entry. Beside that:. Good to know. Suggestion: 95% of local bandwidth is available, but I'll switch to single cores as a test if the turned off firewall still has the 4 cores failing. |
Laurence CERN Send message Joined: 12 Sep 14 Posts: 1161 Credit: 342,328 RAC: 0 |
I would argue that cutting-edge science research is not necessarily easy but agree with the observation that the easier it is the more volunteers we will get. |
|
Send message Joined: 29 Apr 19 Posts: 13 Credit: 109,352 RAC: 0 |
Did you check your firewall? The machine's Windows firewall is off. The router's firewall was blocking incoming traffic on 8080 and 3128 (is CMS using an ATLAS port?). I setup a port forwarding rule to the computer in question with port list: UDP, TCP: 3125, 8080, 23128, 3128, 5222, 9094, 9618, 4080, 1094, 8443, 9133, 9135, 9148, 9149, 9166, 9196, 9199 (per http://lhcathome.web.cern.ch/test4theory/my-firewall-complaining-which-ports-does-project-use) The router open-sessions log now shows several connections from the machine's IP to: 137.138.156.85:9618 (vocms0840.cern.ch) 128.142.142.167:9618 (vccondor01.cern.ch) 128.142.168.202:3125 (vocms0322.cern.ch) 131.225.205.134:3125 (cmssrv245.fnal.gov) but then the sessions all close during the benchmark phase. After HTCONDOR Ping message appears a couple sessions return connecting to 137.138.156.85:9618 TCP, but network traffic from the VM is still glacial After the new port forwarding rule and router reset, the last 3 CMS 4-core still failed at the 786-788 second mark: https://lhcathomedev.cern.ch/lhcathome-dev/result.php?resultid=2772898 https://lhcathomedev.cern.ch/lhcathome-dev/result.php?resultid=2772841 https://lhcathomedev.cern.ch/lhcathome-dev/result.php?resultid=2772298 Is this IP part of the LHC network that is still being blocked after adding the port forwarding rule (if so then my new rule is corrupted/not being followed)? Blocked incoming TCP connection request from 5.188.206.251:8080 to xxx.xxx.xxx.xxx:5022 What changed since my computers were running LHC@Home is some issue had me on the phone with the ISP and they refused to offer any assistance till I reset the router to factory defaults. Saved the router config, but only a backup from 3+ years ago would restore. Lost (and forgot all about) the entries for LHC. The WU all fail with precise timing at 787-/+1 sec. The machine is on too-many-error lockout till tomorrow. Next I can try putting it in a demilitarized zone outside the router's firewall with only it's built-in firewall or just try single cores. |
|
Send message Joined: 29 Apr 19 Posts: 13 Credit: 109,352 RAC: 0 |
The new direction LHC is taking, and the changes they make to how BOINC is used, may spread to many other projects. It's important work that may be widely imitated; so I am just arguing for ease-of-use to be a top priority. Maybe each project handing out a pre-setup VM, containing a BOINC installation attached to their project, will become common. Turn-key operation is, by definition, supposed to be very user-friendly. Users shouldn't have to be required to create port-forwarding rules in their, possibly, ISP rented router... I just signed up for my 49th project and have reached 100+ hours in 160+ WU's and keep spreadsheet data of performance, plus setup problems (doh, bet the port rules are in the spreadsheet from 2016...), for most of those WU's. Honestly, LHC@home WU's were some of the hardest to get functioning optimally. If you want other opinions from BOINCers that have way more experience than I (240x 100+ hour WU's, 80+ projects), ask over at WUProps forums http://wuprop.boinc-af.org/forum_index.php about how LHC@home compares to other projects in ease of use. Have a good weekend. |
|
Send message Joined: 28 Jul 16 Posts: 544 Credit: 400,710 RAC: 0 |
I'm wondering if I simply misunderstand what you mean or if you don't understand how a firewall works and what the portlists describe. The machine's Windows firewall is off. OK, as long as your router's firewall is between the computer and the internet. The router's firewall was blocking incoming traffic on 8080 and 3128 Incoming usually means traffic from the internet to your LAN. On 8080/3128 usually means that the destination port is one of the mentioned. In case of LHC@home this would describe the wrong direction as packets from your LAN have (nearly) arbitrary source ports and will be send to 8080/3128 of an external system. Packets replied by that system will have 8080/3128 as source and the arbitrary port your system has sent as it's source will now be the destination port. is CMS using an ATLAS port? Do you mean 8080/3128 are ATLAS ports? Well, ATLAS tasks use them also but they are standard network ports mainly for HTTP (8080) or a squid proxy (3128). I setup a port forwarding rule to the computer in question Why a forwarding rule? "Forwarding" is usually used to describe a rule that allows traffic from elsewhere to a computer inside your LAN. Do I misunderstand that and your "computer" means a system located elsewhere? The router open-sessions log now shows several connections from the machine's IP to: OK. All of them are necessary, but more interesting would be what connections are blocked by your firewall. Is this IP part of the LHC network that is still being blocked after adding the port forwarding rule (if so then my new rule is corrupted/not being followed)? This looks like a reply I described above (source 8080, destination 5022) A router firewall is usually configured via outgoing rules and automatically allow the corresponding incoming replies until a timeout closes the connection. Simple routers use default timeouts (depending on the model), good routers allow to configure the timeouts. some issue had me on the phone with the ISP and they refused to offer any assistance Most of them don't know what you (or LHC@home) really need and they will be afraid of being made responsible if your firewall is open for malware. I reset the router to factory defaults This may configure only a few rules to allow standard traffic like DNS or HTTP. Next I can try putting it in a demilitarized zone outside the router's firewall Bad idea. You'd better try to understand how to configure your firewall. |
|
Send message Joined: 28 Jul 16 Posts: 544 Credit: 400,710 RAC: 0 |
Just noticed: http://lhcathome.web.cern.ch/test4theory/my-firewall-complaining-which-ports-does-project-use The FAQ doesn't mention that CMS requires a firewall rule that allows connections to TCP 8000, e.g. to klei.nikhef.nl. @Laurence Be so kind as to move 8000 and 8080 from ATLAS/CMS to the list of common ports (HTTP). |
|
Send message Joined: 29 Apr 19 Posts: 13 Credit: 109,352 RAC: 0 |
Why a forwarding rule? Because I wanted to set rules for the specific machine attempting to run the CMS WU and leave the rest of the network rules alone. some issue had me on the phone with the ISP and they refused to offer any assistance I've spent thousands of hours on tech support calls; I'm well aware of their motivations. I needed them to assign me a new IP and they kept refusing so, in that instance, I played along. I'm wondering if I simply misunderstand what you mean or if you don't understand how a firewall works and what the portlists describe. Next I can try putting it in a demilitarized zone outside the router's firewall It's not a great risk to put a machine in the demilitarized zone. Worst case, restore from backups. It's just a BOINC machine; not a machine w/ personal information. Been a computer support technician since 1993... So please don't assume everyone that asks for help is a beginner. Not all of us are so prideful that we won't ask for help when we need it. Besides, I made it clear that the issue seemed to not be with my configurations in my first post and that has proven to be the case. Anyway, it was nice that you tried to help, but this was all a waste of diagnostic time. This machine, with it's firewall back on, the port forwarding rules removed, is running a single core CMS job without issues. https://lhcathomedev.cern.ch/lhcathome-dev/result.php?resultid=2774249 Another machine in my network, which always had it's firewall on, and no port forwarding rules set, ran 1 successful and 1 failed single core CMS. https://lhcathomedev.cern.ch/lhcathome-dev/result.php?resultid=2773064 Indeed a very poor download rate. Yes, the issue is responsiveness at the server, or bandwidth along the network path beyond my local ISP, causing the client to time-out when attempting 4 core WU's. My local bandwidth is neither overwhelmed nor too slow as it had a full 19mbit/s available when several of the CMS jobs failed that all showed maximum 5kbit/sec transfer rates (the CMS VM never demanded more than 0.0025% of my available bandwidth). The issue has nothing to do with my local configurations. |
|
Magic Quantum Mechanic Send message Joined: 8 Apr 15 Posts: 1019 Credit: 18,565,973 RAC: 20,586 |
https://lhcathomedev.cern.ch/lhcathome-dev/result.php?resultid=2775274 Always love these 7 hour crashes ........2 others still running that started around the same time so maybe they will run 8 hours before doing this again. |
|
Magic Quantum Mechanic Send message Joined: 8 Apr 15 Posts: 1019 Credit: 18,565,973 RAC: 20,586 |
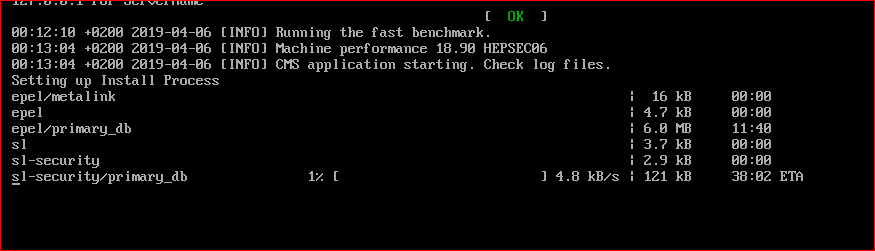 THIS takes way too long......and that *benchmark needs to change its name to *running really slow benchmark* These tasks would run if they didn't take 20 minutes to run that benchmark and then that *security* snail. I am actually typing this and making the img link as I am waiting for the security thing to finish the d/l......just passed 22mins running so I know this will NOT run and after an hour and about 5 minutes it will become a Computer Error. Well it isn't MY computers and with a speed test I have it running at 900Kbps.....that isn't the fastest but it isn't the slowest either Still only to 50%......and for whatever reason it is about 11MBs WHY????.....this slow benchmark and security d/l is ridiculous I will just have to give up here until my new month of my internet speed starts on June 13th........Boinc uses ALL of my high-speed in 10 days or less every month and then VB for whatever reason that is nothing to do with *science* continues to do this. I have hundreds.....or thousands of examples here and at LHC and the thousands of VB tasks the last 8 years. Now if the would run like maybe the Einstein tasks there would be millions of Valids instead of this (not that I want these to switch to GPU) (still only made it to 60%).......and I'm not a typer as fast as the LHC either. Mad Scientist For Life 
|
|
Magic Quantum Mechanic Send message Joined: 8 Apr 15 Posts: 1019 Credit: 18,565,973 RAC: 20,586 |
Well I decided to give this another try on another pc......after about 45hrs just to d/l this 1.14GB vdi (if I still had that on the other pc I would just copy it and move it to this one but I just did a clean reinstall OS) BUT is there a reason we run version 49.00 here and over at LHC ?? |
|
Magic Quantum Mechanic Send message Joined: 8 Apr 15 Posts: 1019 Credit: 18,565,973 RAC: 20,586 |
https://lhcathomedev.cern.ch/lhcathome-dev/result.php?resultid=2786572 Sure would be nice if there was an actual reason for these. 1 (0x00000001) Unknown error code doesn't tell me much other than it is always the problem. Some run 3hrs and this one almost 5hrs https://lhcathomedev.cern.ch/lhcathome-dev/results.php?hostid=1866 But this pc turns in a Valid one minutes later. (I guess I could go check all of them over at LHC and see how things are running since for some reason it is the same version 49.00 ) I think I will switch this over to another pc just like this one but with 24GB ram.........not that it should be the problem since I have this running on a laptop with what they call 8GB ram but only gets to use 6.9GB |
|
Magic Quantum Mechanic Send message Joined: 8 Apr 15 Posts: 1019 Credit: 18,565,973 RAC: 20,586 |
https://lhcathomedev.cern.ch/lhcathome-dev/workunit.php?wuid=1905820 Well I hope we don't start getting these over at LHC  Reminds me of Sixtrack credits back in 2004 Another one running on this same host is getting close to finished so lets see if I can get a .75 credit for one of these. |
|
Magic Quantum Mechanic Send message Joined: 8 Apr 15 Posts: 1019 Credit: 18,565,973 RAC: 20,586 |
https://lhcathomedev.cern.ch/lhcathome-dev/workunit.php?wuid=1905853 Just as I expected Run time 19 hours 13 min 32 sec CPU time 1 days 5 hours 7 min 41 sec Validate state Valid Credit 78.82 |
|
Magic Quantum Mechanic Send message Joined: 8 Apr 15 Posts: 1019 Credit: 18,565,973 RAC: 20,586 |
|
|
Magic Quantum Mechanic Send message Joined: 8 Apr 15 Posts: 1019 Credit: 18,565,973 RAC: 20,586 |
https://lhcathomedev.cern.ch/lhcathome-dev/result.php?resultid=2790816 These are the most annoying VB tasks ever. Two Valids and then 2 of these on a pc with 24GB ram on the i7 Intel 8 core I decided to give them another try and get 9 Valids on 5 different pc's so as usual I trust them to run and now when I decided to make a 2am check I see some running and several failed and are now running another pair of 2-core tasks but I set them to getting no more tasks again and see if any of this running batch will finish Valid next time I check. [ERROR] Condor ended after 20221 seconds. <--- just got 3 of these [ERROR] Condor ended after 2132 seconds <-- and 2 of these |

©2026 CERN