Message boards : CMS Application : New version 49.00
Message board moderation
Previous · 1 · 2 · 3 · 4 · 5 . . . 6 · Next
| Author | Message |
|---|---|
|
Send message Joined: 22 Apr 16 Posts: 749 Credit: 2,976,995 RAC: 27,301 |
2019-03-27 15:20:07 (1392): Guest Log: VBoxService 5.2.6 r120293 (verbosity: 0) linux.amd64 (Jan 15 2018 14:51:00) release log Is it possible to upgrade to 5.2.8 (Official from Boinc) or last Version.5.2.26 for the next applet? |
 Magic Quantum Mechanic Magic Quantum MechanicSend message Joined: 8 Apr 15 Posts: 805 Credit: 14,339,071 RAC: 7,975 |
Got 3 of these in a row Guest Log: [ERROR] Condor ended after 1153 seconds. Now 2 more running and since they are at 4hrs run time I hope they will continue to the end with *jobs* My other hosts are back running these again after a light-year of time to d/l this version (it seemed like it) |
|
Magic Quantum Mechanic Send message Joined: 8 Apr 15 Posts: 805 Credit: 14,339,071 RAC: 7,975 |
|
|
ivan Send message Joined: 20 Jan 15 Posts: 1145 Credit: 8,310,612 RAC: 0 |
https://lhcathomedev.cern.ch/lhcathome-dev/results.php?userid=192 Link's not working for me; check your privacy settings. 
|
|
Magic Quantum Mechanic Send message Joined: 8 Apr 15 Posts: 805 Credit: 14,339,071 RAC: 7,975 |
(I NEVER have liked the damn way they use urls' on these boinc pages) After no problems here from the start with this new CMS version the last few days mostly problems and several versions. [ERROR] Could not connect to lhchomeproxy.cern.ch on port 3125 2019-04-05 12:43:02 (6004): Guest Log: [INFO] Shutting Down. 2019-04-05 12:43:02 (6004): VM Completion File Detected. 2019-04-05 12:43:02 (6004): VM Completion Message: Could not connect to lhchomeproxy.cern.ch on port 3125 [ERROR] Condor ended after 1216 seconds. 2019-04-04 18:39:16 (6000): Guest Log: [INFO] Shutting Down. 2019-04-04 18:39:16 (6000): VM Completion File Detected. 2019-04-04 18:39:16 (6000): VM Completion Message: Condor ended after 1216 seconds. and this mess https://lhcathomedev.cern.ch/lhcathome-dev/result.php?resultid=2762565 Here is that snapshot where it looks like to me it as usual prefers a server that is a stones throw from Geneva and not across the Atlantic and then across North America since I watch them and see if they are fast (sort of) or typical slow........which should not be making it such a problem just to start a task considering we have to spend hours to d/l the tasks and the original vdi (no squids please) 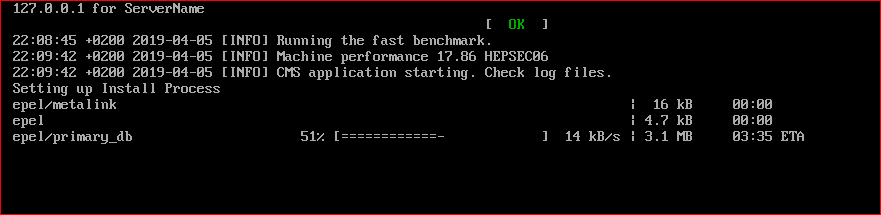 |
|
Magic Quantum Mechanic Send message Joined: 8 Apr 15 Posts: 805 Credit: 14,339,071 RAC: 7,975 |
https://lhcathomedev.cern.ch/lhcathome-dev/result.php?resultid=2765653 At least this one only wasted 8mins before 1 (0x00000001) Unknown error code as I watched the log and VM console run Same old thing......6mins for the server to get to - Theory application starting. Check log files. 00:09:01.102259 VMMDev: Guest Log: [DEBUG] HTCondor ping 00:09:07.889805 VMMDev: Guest Log: [DEBUG] 0 And then sit there waiting for the job to start in the slots long enough for it to end up an Error instead of VMMDev: Guest Log: [INFO] New Job Starting in slot1 ....on most of them and then several other Error versions. And since I have seen this hundreds of times it is just because the server does not go through all the same old checking of my computers fast enough and actually never just goes right to work. Sure would be nice if when I already have the files and vdi and tasks d/l here that they could just start running instead of hoping Cern can do the server hand shake and get to work instead of just sitting there.at Theory application starting. Check log files. VMMDev: Guest Log: [DEBUG] HTCondor ping VMMDev: Guest Log: [DEBUG] 0.....and waiting to start the *jobs* Here is the one I just watched as I am typing this......  two in a row the same thing https://lhcathomedev.cern.ch/lhcathome-dev/result.php?resultid=2765653 and several more of these on another pc - [ERROR] Condor ended after 1272 seconds. Mad Scientist For Life 
|
|
Magic Quantum Mechanic Send message Joined: 8 Apr 15 Posts: 805 Credit: 14,339,071 RAC: 7,975 |
Well since Ivan was getting all those Valid CMS tasks I decided to give it another try and got 2 Valids followed by 3 of these time wasting Errors https://lhcathomedev.cern.ch/lhcathome-dev/result.php?resultid=2770411 I have 2 new ones started but I will have to set the manager back to no new tasks......and see if these 2 make it beyond 1hr 40mins. |
|
ivan Send message Joined: 20 Jan 15 Posts: 1145 Credit: 8,310,612 RAC: 0 |
You *may* have been unlucky with your timing. Since the resolution of the Easter problem ("quota exceeded", I've yet to get a full explanation) there have been a number of "unknown" entries showing up in the job plots. So, I submitted a new batch last night, waited until it showed up in my monitor, then aborted the previous batch -- this is also why there is a large "cancelled" peak in the plots. Let's wait a few more hours to see if things settle down, though I'm concerned that I'm still seeing unknowns in the plots.
|
|
Magic Quantum Mechanic Send message Joined: 8 Apr 15 Posts: 805 Credit: 14,339,071 RAC: 7,975 |
Ok Ivan I did get 2 more Invalids so I will try a couple more in my morning (noon) saturday |
|
Magic Quantum Mechanic Send message Joined: 8 Apr 15 Posts: 805 Credit: 14,339,071 RAC: 7,975 |
No luck here Ivan Another 10 and probably soon 12 Errors so I will switch back to some Theory tasks and wait for this problem to be fixed here. |
|
Send message Joined: 13 Feb 15 Posts: 1242 Credit: 964,086 RAC: 490 |
Another 10 and probably soon 12 Errors so I will switch back to some Theory tasks and wait for this problem to be fixed here.Picked up 1 task to test how it's going here. It's running fine. 4th job (40,000 events) inside the VM running. |
|
Magic Quantum Mechanic Send message Joined: 8 Apr 15 Posts: 805 Credit: 14,339,071 RAC: 7,975 |
|
|
ivan Send message Joined: 20 Jan 15 Posts: 1145 Credit: 8,310,612 RAC: 0 |
https://lhcathomedev.cern.ch/lhcathome-dev/workunit.php?wuid=1891941 That looks like (a small) progress to me. Did you change anything? I'm still perplexed as to why the job plots are showing so many "unknown" status jobs. For the record, WMAgent monitoring suggests no failures in Volunteer MonteCarlo jobs (i.e. no job has failed more than 3 (5?) attempts at running). OTOH, operations change the core submissions software quite often, they may have changed criteria...
|
|
Magic Quantum Mechanic Send message Joined: 8 Apr 15 Posts: 805 Credit: 14,339,071 RAC: 7,975 |
https://lhcathomedev.cern.ch/lhcathome-dev/workunit.php?wuid=1891827 The very next task after that Valid one is another one of these. (no I didn't change anything) 36 Valids 31 Errors so far and usually the same error |
|
ivan Send message Joined: 20 Jan 15 Posts: 1145 Credit: 8,310,612 RAC: 0 |
https://lhcathomedev.cern.ch/lhcathome-dev/workunit.php?wuid=1891827 Looking at some of the timings suggests that something is hanging for quite a while, then after Condor is contacted it times out at ~20 minutes without returning a job.
|
|
Send message Joined: 13 Feb 15 Posts: 1242 Credit: 964,086 RAC: 490 |
It's probably not a problem, but in the vdi coming from the project, the log-files MasterLog, StartLog and StarterLog exist and aren't empty. There are remnants of logging's from March 25th in it. |
|
Magic Quantum Mechanic Send message Joined: 8 Apr 15 Posts: 805 Credit: 14,339,071 RAC: 7,975 |
https://lhcathomedev.cern.ch/lhcathome-dev/result.php?resultid=2771779 After midnight PDT I started a CMS hoping the internet speed was running fast enough to get the job/slots started and watched it and when it was running several hours I knew it was going to complete and it just finished Valid Run time 12 hours 54 min 30 sec CPU time 14 hours 42 min 22 sec using 2 cores And noticed CP started a CMS 10 minutes after I did and his was a short one but also Valid https://lhcathomedev.cern.ch/lhcathome-dev/result.php?resultid=2771626 So late tonight I will fire up two of the 2-core CMS and see if they are going to run ( you can see all about that in a pm to you over at LHC Ivan) And I took a couple new snapshots of this one last night just in case ( I probably have other ones in my stash) |
|
ivan Send message Joined: 20 Jan 15 Posts: 1145 Credit: 8,310,612 RAC: 0 |
It's probably not a problem, but in the vdi coming from the project, the log-files MasterLog, StartLog and StarterLog exist and aren't empty. Ah, so that's what that is! I had two tasks fail tonight and I noticed the strange time-stamps in the output.
|
|
Magic Quantum Mechanic Send message Joined: 8 Apr 15 Posts: 805 Credit: 14,339,071 RAC: 7,975 |
https://lhcathomedev.cern.ch/lhcathome-dev/result.php?resultid=2772069 Well when I started two of the 2-core tasks after midnight where I knew the isp speed would be fast enough and both ran complete Valid tasks. But today I had to try starting a new one when the internet speed was not quite as fast and watched it run and after about 3 hours it finally stopped with the usual Guest Log: [ERROR] Condor ended after 8517 seconds This is always a problem connecting and communicating with the Cern server from where I am and I have watched thousands of logs and VB Console runs of these tasks. If the speed is fast enough (like when you live withing 500 miles of Geneva) these tasks start in just a few minutes but like this one I watched it take 28 minutes just to get to HTCondor Ping which is a sign that there is no way this will run a complete Valid and in this case running for 3 hours before it is an Error. Watching the VB Console I see Setting up install process epl/primary_db takes too long followed by the sl-security/primary_db taking too long with task run time over 20 )....and finally HTCondor Ping at 28mins and then run for another 2.5 hours I know every time that security check and the EPL File Extension run slow and finally finish that the task will never run Valid 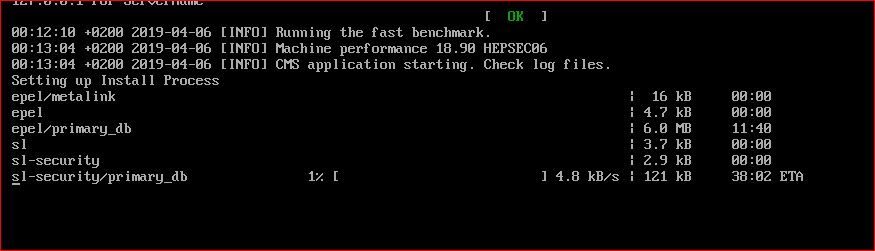 Just hangs up there and always end up the same. So I will do the same thing and start up a couple new ones after midnight (I always run a fast speed test just to be sure) |
|
Send message Joined: 28 Jul 16 Posts: 520 Credit: 400,710 RAC: 0 |
Indeed a very poor download rate. This may partly be caused by an overloaded local internet connection, but especially in case of the EPEL downloads it could also be caused by a slow mirror server. LHC@home doesn't host the files shown in the graphics on their own servers. Instead they link to the public EPEL repository. The local downloader then pics one of the mirrors from this list: https://admin.fedoraproject.org/mirrormanager/mirrors/EPEL The mirror's bandwidth vary between poor 50 kbit/s and excellent 40000 kbit/s and for some unknown reason it's always a very slow mirror that is tried first (own experience). What can be done? 1. LHC@home could mirror the required files on their own systems and distribute them via fast networks, e.g. own CVMFS or openhtc.io. 2. Volunteers could configure their local firewall to reject connections to slow mirror servers. The local downloader would then immediately pic another mirror from the list. 3. Volunteers using a local proxy could do the following: 3.1 Reject connections to slow mirrors and to mirrors using HTTPS. 3.2 Pic 1 fast and reliable mirror from the list and rewrite all URLs to other mirrors to point to that fast mirror. As a result all requests would be served from the proxy cache except outdated files that would be downloaded from the remaining fast mirror. It should be mentioned that the total size of the EPEL downloads is tiny compared to the total downloads a CMS VM requires until it is completely set up. The total size is far more than 100 MB and nearly all of it could be served by a local proxy. |

©2025 CERN