Message boards : CMS Application : New version 49.00
Message board moderation
Previous · 1 · 2 · 3 · 4 · 5 · 6 · Next
| Author | Message |
|---|---|
 Magic Quantum Mechanic Magic Quantum MechanicSend message Joined: 8 Apr 15 Posts: 1018 Credit: 18,548,594 RAC: 20,045 |
So far starting up these tasks again (on the 13th) I have 32 Valids and 7 Error tasks (X2-core) I watch them all start since I have to wait for the *bonus* high-speed I get between 2am and 8am (since Cern uses up my 10GB high-speed in 24 hours) And I get this late night 50GB until it is used up at Cern (still have 81% of that left after 4 days) If you watch a CMS task start running in the RDC you can see it has to run through all the usual VB start-ups but then has to d/l several more things and I have seen if you are not running a high-speed internet those are so slow that they take hours and then crash BUT when running at high-speed (I have 25Mbps at best) they only take a few seconds to d/l the primary,security,and singularity files and then finally get to HTCondor ping and you can tell they will run if this all happens in less than 12 minutes.........if not they end up with at times over 5 hours of wasted time. Now I know I am not the only person that doesn't get high-speed 24/7 365 so these have to just end up error after error if they try to run these on several pc's and running several different tasks on every core they have and that ends up as many threads asking why they get these errors. Now I could pay Hughes satellite $150 per month to get the high-speed of 50GB during normal hours and another 50GB late-night if I had lots of cash to give to someone else just because........but since I'm retired now that would be insane to do that......not to mention I would use all of those 100GB d/l for Cern in about 3 weeks so it would still not be enough. So.......I will run these starting at 2am every day until I use up the last 40.7 GB here and then just switch back to Sixtracks and a few Theory over there since they don't need as much speed to start running.......and a few GPU's at Einstein since they also do not depend on constant internet up and downloading. In fact after d/ling Sixtracks or GPU's you can unplug the modem and let the tasks all run and send them back later and then be sure that I don't lose data transfer at all. |
|
Send message Joined: 28 Jul 16 Posts: 544 Credit: 400,710 RAC: 0 |
... d/l the primary,security,and singularity files ... This should not occur any more since Laurence removed the Singularity update from the bootstrap script this afternoon. I already got a CMS task from the prod server that used the new bootstrap and it works fine. Regarding the rest of your post: You describe a typical scenario where a local squid can be very helpful. And since the project modifications a while ago it is no longer a must to install it on linux. See the links: https://lhcathomedev.cern.ch/lhcathome-dev/forum_thread.php?id=475&postid=6396 https://lhcathome.cern.ch/lhcathome/forum_thread.php?id=4611&postid=36101 |
|
Magic Quantum Mechanic Send message Joined: 8 Apr 15 Posts: 1018 Credit: 18,548,594 RAC: 20,045 |
Well that sure made a difference ( I will just pretend it was from somebody finally believing me and taking a look at the RDC as these had to finally start a task running) The "Fast Benchmark* was about 200 seconds and then only about 5 seconds to get to HTCondor ping None of that previous d/l had to be done ( d/l the primary,security,and singularity files ) And the fact is that *security* d/l before was the slowest of all and I sure was glad that was gone so now I have all 8 tasks up and running and it didn't take 90 minutes this time so I am actually off here by 2:45am So this should make a big difference over at LHC (well I hope there isn't a jinx and they all crash while I am asleep now) .......goodnight |
|
Magic Quantum Mechanic Send message Joined: 8 Apr 15 Posts: 1018 Credit: 18,548,594 RAC: 20,045 |
Tried another test this morning and still these will not start because of the Cern server problems. https://lhcathomedev.cern.ch/lhcathome-dev/result.php?resultid=2792997 |
|
ivan Send message Joined: 20 Jan 15 Posts: 1156 Credit: 8,453,729 RAC: 6 |
Tried another test this morning and still these will not start because of the Cern server problems. Yes, we're having condor problems. WMStats shows jobs pending, but the condor schedd isn't sending any out. Must be a ClassAd mismatch that arose since the reboots.  |
|
Magic Quantum Mechanic Send message Joined: 8 Apr 15 Posts: 1018 Credit: 18,548,594 RAC: 20,045 |
Well I guess I have to give up on these CMS again. Last night when my new month of high-speed ISP started and I ran a quick test to see that it was running full speed I started these up againand once again they ran 5+ hours and did the same old thing [ERROR] Condor ended after 18746 seconds. Incorrect function https://lhcathomedev.cern.ch/lhcathome-dev/workunit.php?wuid=1914971 One example but all 12 failed but 4 more started and have been running about the same amount of running time so I will let them run and see what they do. I have no problem running the Theory VB tasks over at LHC so it isn't a VB problem. |
|
Send message Joined: 28 Jul 16 Posts: 544 Credit: 400,710 RAC: 0 |
Your errors might be caused by firewalled ports. To ensure all required ports are open you may want to run some basic network tests. On Windows 10 open a powershell window and run the following commands: tnc cms-data-bridge.cern.ch -port 443 tnc vocms0840.cern.ch -port 9618 tnc vocms0267.cern.ch -port 4080 tnc cms-frontier.openhtc.io -port 8080 tnc eoscms-srv-m1.cern.ch -port 1094 All tests must succeed otherwise CMS will not run any job. Be so kind as to post the output of the tests. |
|
Magic Quantum Mechanic Send message Joined: 8 Apr 15 Posts: 1018 Credit: 18,548,594 RAC: 20,045 |
Ok I just ran all of those and they are all open (TRUE) I never have had any blocked ports before so I knew that was not the problem and since these hosts ran many of these before I knew it wasn't a port problem and I do not even use a firewall since these are Cern only computers. One did the 4 Valids and the other 2 pc's next to it on the same system failed. You are welcome to check my stats and you can see that last month from the 22nd and before where many Valids and then they started failing for me and Ivan but then this month his started working again and mine would run for 5 or 6 hours before crashing and they all had been running jobs until that point. I will run 4 more 2-core on the one host that did get Valids and just let the other get back to running Valid Theory VB's over at LHC Edit: after these 4 mew tasks have been running between 30mins and 1 hour I see this in the VB log Giving up catch-up attempt at a 60 047 182 552 ns lag; new total: 240 055 516 373 ns |
|
ivan Send message Joined: 20 Jan 15 Posts: 1156 Credit: 8,453,729 RAC: 6 |
Ok I just ran all of those and they are all open (TRUE) I think my one Win10 failure was after I upgraded the memory to 8 GB because 4 GB wasn't quite enough and I guess the VM got confused when it restarted. I'm now running 1x 2-core VM on it with no apparent problem. Googling that error message turns up some interesting things. At the moment your i7-3770 seems to be running 4x 2-core VMs (so you must have hyperthreading enabled); is that right? One of the comments I saw was that it's best to keep one core free to run the VM. Others suggested time-outs to slow peripheral storage, mismatch with Guest Addition modules, and a few other more exotic things. |
|
Magic Quantum Mechanic Send message Joined: 8 Apr 15 Posts: 1018 Credit: 18,548,594 RAC: 20,045 |
Yes hyperthread has been enabled and used that way since I started running these 2 years ago. I did the usual google check myself and saw all those exotic things and some basics and none applied to this. (all drivers up to date and all VB and Boinc up to date and this one has 24GB Ram and the other 2 have 16GB ram) These are all Intel i7-3770 CPU @ 3.40GHz No problems running anything else and as I mentioned these 3 pc's ran many,many of these Valid and I always run them the same. Four 2-core CMS tasks and the same with any other LHC tasks here or over at LHC I don't run any CMS over at LHC but I can run all cores with Theory on all of mine and that includes a old 3-core running X86 XP Pro and all the old quad-cores with 12GB ram with Win 10 and 7 run 24/7 and never fail. Makes no sense that these all worked last month with the same CMS version running the exact same way. The ones running right now are on the pc that got the 4 Valids yesterday but I didn't check the VB log so I don't know if it was *Giving up catch-up attempt* so I don't know if it did that last time. BUT since I have watched 10's of thousands of these VB tasks run over the last 9 years I have seen them do that and still run the complete tasks Valid. So now since it is almost 4am I will have to look again in about 8 hours and see if these are still running or once again a [ERROR] Condor ended after 18746 seconds which is after 5 hours of running jobs. Remember both of your Linux machines did the same thing last month and if you take a look right now they are not doing very good either. (check the Error tasks for them) but you also get Valids. (maybe I need 40 cores)  https://uscms.org/uscms_at_work/computing/setup/batch_troubleshoot.shtml Ok 4am..........goodnight and I'll check back later..... |
|
ivan Send message Joined: 20 Jan 15 Posts: 1156 Credit: 8,453,729 RAC: 6 |
Well, my little £130 Celeron J1900 certainly didn't like trying to run a 4-core VM! Continually timed out "Waiting for memory"! I've dropped down to 3 cores to see if that runs. |
|
Send message Joined: 28 Jul 16 Posts: 544 Credit: 400,710 RAC: 0 |
Each of your failed VMs requested 4584MB RAM which is close to 60% of the computer's total RAM. IIRC the default value of RAM a BOINC client allows it's task to use is 60%. Did you try to increase the allowed RAM percentage? |
|
Magic Quantum Mechanic Send message Joined: 8 Apr 15 Posts: 1018 Credit: 18,548,594 RAC: 20,045 |
ALL of mine are always set at 100% CPU and 95% Ram |
|
ivan Send message Joined: 20 Jan 15 Posts: 1156 Credit: 8,453,729 RAC: 6 |
Each of your failed VMs requested 4584MB RAM which is close to 60% of the computer's total RAM. Hah! Didn't think about that. It didn't like 3 cores either -- come to think of it, the error at one point was "waiting for memory"... Yes, it was set to 50/90%, I changed to 90/90%. |
|
Magic Quantum Mechanic Send message Joined: 8 Apr 15 Posts: 1018 Credit: 18,548,594 RAC: 20,045 |
@#%$@%^&&^%$$#@* Well as usual I get about 40 Valids in a row and then........ Might as well show you it isn't just me https://lhcathomedev.cern.ch/lhcathome-dev/results.php?hostid=1054 that evil server always picks the wrong night to do this too Well in the morning (its 2:45am right now) I will be at the bowling alley and every pin will have a picture of my imaginary Cern server on it. |
|
ivan Send message Joined: 20 Jan 15 Posts: 1156 Credit: 8,453,729 RAC: 6 |
@#%$@%^&&^%$$#@* Sorry, there was a huge increase in CMS jobs being run last night, so the queue drained before I could replenish it. New batch sent, should be OK in a few minutes. |
|
Magic Quantum Mechanic Send message Joined: 8 Apr 15 Posts: 1018 Credit: 18,548,594 RAC: 20,045 |
https://lhcathomedev.cern.ch/lhcathome-dev/results.php?hostid=3697 Only good thing is when it doesn't only happen with my CMS tasks after 3am https://i.ibb.co/3SdHx2F/here-we-go-again.png  |
|
Magic Quantum Mechanic Send message Joined: 8 Apr 15 Posts: 1018 Credit: 18,548,594 RAC: 20,045 |
Well as usual I stay up until after 2am (now 3:30am( to get the CMS tasks to start running and once they do I can not have to worry about ISP speed. But this morning (night to me) all I get is this over and over and that means they will run for an hour or so and crash (many many times over the years I have seen this) BUT over at LHC all the tasks start like they should 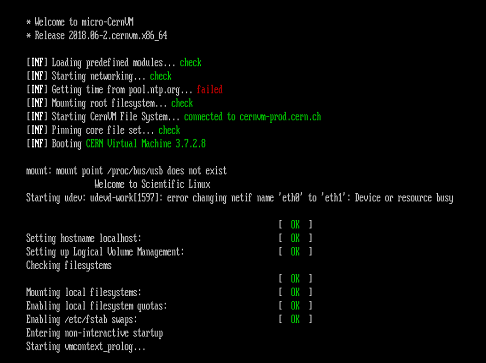 |
|
Send message Joined: 26 Apr 15 Posts: 6 Credit: 10,056,509 RAC: 0 |
I'm finally getting some valid tasks on CMS. The past couple weeks it was 'EXIT_NO_SUB_TASKS' on everything. (I didn't change anything) Nice!  |
|
Magic Quantum Mechanic Send message Joined: 8 Apr 15 Posts: 1018 Credit: 18,548,594 RAC: 20,045 |
Good to hear wHewitt I checked your Windows version and THAT is one thing I never get here....single core tasks getting 10K credits My 2 core and 3 core CMS tasks are always 350 - 1100 Credits each max I guess I will give it another try here after I finish the hundreds of LHC Theory and Sixtrack Tests I just got after rarely getting anything over there. |
{kind=link}

©2026 CERN