Message boards : Number crunching : issue of the day
Message board moderation
Previous · 1 . . . 7 · 8 · 9 · 10 · 11 · Next
| Author | Message |
|---|---|
 ivan ivanSend message Joined: 20 Jan 15 Posts: 1156 Credit: 8,453,729 RAC: 8 |
OK, here's what's happening. Does that mean I have to renew the proxy Oh, b*gger, we seem to have a maximum outage of some sort at work, I can log into the uni's gateway but not to any of my machines. I'm going to have to take a midnight stroll up the road to see if I can recover anything tonight... #Baby it's cold outside,  |
Laurence CERN Send message Joined: 12 Sep 14 Posts: 1161 Credit: 342,328 RAC: 0 |
Rasputin, If you look at the plots on the CMS Jobs page, as long as the running jobs and wall-time plots show less than 10% of jobs failing, I am not too worried. The pie chart shows the failure modes and most of due to stage-out errors, which is not surprising and we can hopefully improve on that over time. From the 5 job ids that you posted, two were failed jobs from different IPs and the other three were not sent. I am still interested to chase down potential errors so please let me know if you think there is one machine that is behaving badly. |
|
ivan Send message Joined: 20 Jan 15 Posts: 1156 Credit: 8,453,729 RAC: 8 |
Seems to be a break in the network to our building, I had indications that intra-building connections were still up. Security chap was spectacularly uninterested until I explained about ten times that the CC has a Network Duty Officer on call 24/7, so eventually he deigned to call someone else to find if they had the NDO's number. I left him with explicit instruction to tell the NDO about the outage when they found the number. (It can't be "if", can it, for such an important function? I'll be following up in high dudgeon Monday morning!) |
|
Send message Joined: 16 Aug 15 Posts: 967 Credit: 1,216,795 RAC: 0 |
Thanks Laurence. I was just trying to point out, that by my interpretation, there was an IP address, that was (is?) producing lots and lots of abandoned task, which would not show as errors on dashboard or any other statistics. However, if there is some kind of mechanism, that causes this, it should be eliminated. There is no real loss to the project, but the volunteer would be wasting his resources. I will keep an eye on it. You have bigger fish to catch, so i will let it be for now. |
|
ivan Send message Joined: 20 Jan 15 Posts: 1156 Credit: 8,453,729 RAC: 8 |
We can track down such hosts (if it's stage-out errors it's usually multiple hosts on the same NAT address). Getting a response from PM or (as a last resort) email is problematic. |
|
Send message Joined: 16 Aug 15 Posts: 967 Credit: 1,216,795 RAC: 0 |
I just had a thought. If people had not noticed the changeover to the new project name and continued, would they not produce lots of abandoned tasks? Like in this case: http://lhcathomedev.cern.ch/vLHCathome-dev/forum_thread.php?id=78&postid=2345 |
|
Send message Joined: 16 Aug 15 Posts: 967 Credit: 1,216,795 RAC: 0 |
A 2nd? run started.Has this been fixed? Now it is back to where it was. No 2nd run. 2016-03-12 13:18:19 (3052): Guest Log: [INFO] No more jobs. Shutting down! |
|
Send message Joined: 16 Aug 15 Posts: 967 Credit: 1,216,795 RAC: 0 |
Apologies to all involved. My posts about the aborted jobs all from the same IP---that was me. I just discovered, that a new IP was assigned to me. It has been the same fore a long time, so i never rechecked. Mea culpa--will be more careful next time. |
|
ivan Send message Joined: 20 Jan 15 Posts: 1156 Credit: 8,453,729 RAC: 8 |
Dinnae fash yersel, Jimmy, it coud happen t'annyone. |
|
Magic Quantum Mechanic Send message Joined: 8 Apr 15 Posts: 1007 Credit: 18,449,459 RAC: 19,511 |
Mo chreach |
|
Send message Joined: 16 Aug 15 Posts: 967 Credit: 1,216,795 RAC: 0 |
éí ííníyą́ąʼgo naaʼdidoolyééł |
|
Magic Quantum Mechanic Send message Joined: 8 Apr 15 Posts: 1007 Credit: 18,449,459 RAC: 19,511 |
Navajo ??? Btw while I'm here I still get these in a batch after having one that claims to be Valid http://atlasathome.cern.ch/result.php?resultid=4191239 VM Heartbeat file specified, but missing. 2016-03-12 16:37:08 (3616): VM Heartbeat file specified, but missing file system status. (errno = '2') So I guess as far as my test host goes that new version only works when it feels like it (it has a heart I am pretty sure) Oy Vey I know VB is running since it has no problem with vLHC or Atlas I NEVER tried a *suspend* or *reboot* just because I wouldn't mind if they worked all the time instead of how it does. (Windows 10) .....looks like Kansas will win this game (it also says I have one in progress but I do not.....but it did this once before) |
|
Send message Joined: 20 Mar 15 Posts: 243 Credit: 901,716 RAC: 0 |
I just had a thought. If people had not noticed the changeover to the new project name and continued, would they not produce lots of abandoned tasks? Another thought. If someone is using an app_config file this will be lost when they detach and re-attach. Is the app name still the same (CMS)? |
|
Send message Joined: 13 Feb 15 Posts: 1281 Credit: 1,048,302 RAC: 63 |
If someone is using an app_config file this will be lost when they detach and re-attach. Is the app name still the same (CMS)? app-names CMS and LHCb |
|
Magic Quantum Mechanic Send message Joined: 8 Apr 15 Posts: 1007 Credit: 18,449,459 RAC: 19,511 |
This is the first time I ever got these tasks on this 8-core computer 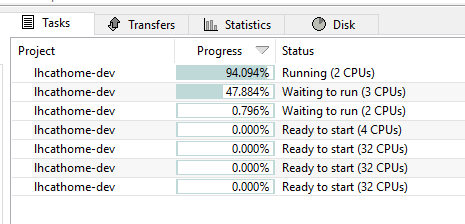 First pc of the day for me to check so I thought my eyes were blurry still so I hope the rest of them don't have 32-core tasks loaded. Not sure why this happened or what will happen next and for some reason it is only running the one 2-core task and the others are just waiting (2,3,and 4 core tasks) It had been running 2-core tasks since those started here. Mad Scientist For Life 
|
|
ivan Send message Joined: 20 Jan 15 Posts: 1156 Credit: 8,453,729 RAC: 8 |
What application/jobnames? |
|
Send message Joined: 21 Feb 17 Posts: 21 Credit: 195,770 RAC: 0 |
This is related to some tests we ran on the scheduler and at some point tasks that use the MAX_CPUS were sent. Please delete these tasks as they will not run. New tasks should be sent with the correct preferences. Sorry for the inconvenience. |
|
Send message Joined: 13 Feb 15 Posts: 1281 Credit: 1,048,302 RAC: 63 |
Not sure why this happened or what will happen next and for some reason it is only running the one 2-core task and the others are just waiting (2,3,and 4 core tasks) Somehow the server thinks (temporary) the machine has 32 cores and also ignored your preferences. BOINC probably allocates the memory belonging to a 32 core task for the other tasks too and therefore will not start a second task because BOINC thinks no memory enough for such a huge memory demanding task. |
|
Magic Quantum Mechanic Send message Joined: 8 Apr 15 Posts: 1007 Credit: 18,449,459 RAC: 19,511 |
These are Theory tasks and of course they only ran for the 25mins until they figured out there were no 32 cores ready for it (I only saw the first one start and do that) and I let the one that was running (2-cpu) finish and while I was outside it tried the other two and sent them back Invalid and went back to running and completing the 2,3,and 4 core tasks I was testing. After they were finished I switched this one to run 3-core tasks X2 on this 8-core. Of course I went right up and checked the other 5 pc's I had running and since I had both vLHC-dev and LHC Theory tasks (and SixTrack) running it had not got to the point of getting new tasks here.......so I let them finish all those tasks and reloaded them with vLHC Theory X2 tasks on those 32 cores (5 separate computers) Back to normal.....but it was a bit strange which is why I had to take a snap shot of that  (Edit: Oh btw while I am here,when I check my own account Computers page here it has not been updating them since June 23rd and I tend to use that just to see when a computer has contacted the server so I can see that from this laptop instead of going upstairs to look at each one every time) Mad Scientist For Life
|
|
Tern Send message Joined: 21 Sep 15 Posts: 89 Credit: 383,017 RAC: 0 |
"Server error: feeder not running" |

©2026 CERN