Message boards : News : No new jobs
Message board moderation
Previous · 1 · 2 · 3 · 4 · 5 · 6 · 7 . . . 13 · Next
| Author | Message |
|---|---|
 ivan ivanSend message Joined: 20 Jan 15 Posts: 1156 Credit: 8,453,729 RAC: 298 |
So why does the graph not even show a dip, when we know, there was no work running for several hours? Well, for one, there were still slow jobs from the previous batch trickling in; for another Dashboard didn't necessarily know immediately that I'd canned the jobs. Dashboard is intrinsically always behind times and is a cause of lots of confusion and bewilderment in the CMS community -- for example the second graph seems to overstate the number of failed jobs because these are later realised to have succeeded but the data aren't adjusted a posteriori. So really they should be taken with a grain of salt -- "objects in the rear mirror may be closer than they appear". [Edit] I'll add a link to a graphic showing the command and data flow of CMS@Home when I get the chance, tho' it currently doesn't show how and where Dashboard hooks into it. It's not going to be easy to do from home so I might leave it for Monday afternoon or so; I need to do some gardening for the first time in about five years this weekend... :-( [/Edit]  |
|
ivan Send message Joined: 20 Jan 15 Posts: 1156 Credit: 8,453,729 RAC: 298 |
I did ask if I could break it... Well done that volunteer! I'd encourage you to make that report, looks like an internal (if highly obscure) bug that needs to be squashed [if only by restricting public access...]. I understand that one testing technique in vogue these days is to throw random input at a process; it tests robustness against incorrect input and may show up vulnerabilities before the black-hats find them. Of course it also points out the need for a more-intuitive user interface, I'll admit Dashboard isn't the easiest thing to drive. |
|
PDW Send message Joined: 20 May 15 Posts: 217 Credit: 6,294,052 RAC: 0 |
I've moved onto .. The server failed to serve your request, please retry. In case of new failure contact the admin. I'll have another go tomorrow and try to reduce it to the least amount of clicks to make it reproducible before I report it. |
|
ivan Send message Joined: 20 Jan 15 Posts: 1156 Credit: 8,453,729 RAC: 298 |
Cheers! |
|
Send message Joined: 16 Aug 15 Posts: 967 Credit: 1,216,795 RAC: 0 |
Just to confirm. Site T3s T3_CH_Volunteers That is us, users working trough boinc cms-dev project? |
|
ivan Send message Joined: 20 Jan 15 Posts: 1156 Credit: 8,453,729 RAC: 298 |
Just to confirm. Yes, we are now officially CMS site T3_CH_Volunteer (no "s"). T3 means Tier 3 (Tier 0 is CERN, Tier 1 is large (usually national) centres (RAL in the UK, INFN in Italy, FNAL in the US...), Tier 2 are the regionals (London, Scotgrid, etc.) and Tier3 are sites not expected to host data, just allow use by "local" users, so usually at a departmental scale); CH is Switzerland of course, and Volunteer is mainly self-explanatory. |
|
Send message Joined: 15 Apr 15 Posts: 47 Credit: 1,142,690 RAC: 0 |
So we are officially contributing results to the larger simulation database? |
|
ivan Send message Joined: 20 Jan 15 Posts: 1156 Credit: 8,453,729 RAC: 298 |
So we are officially contributing results to the larger simulation database? No, not yet. Apart from anything else we need "validation" before our results are trusted. I'll remind you of the "-dev" suffix in our name... We hope to make a large step towards that recognition when I give a presentation at CERN on the 15th (Major panic today when I was booking my flights; after my bank accepted my credit card but before BA could confirm my booking, ba.com went belly-up! Luckily I eventually got a confirmation e-mail from them an hour or two later.) What I hope to do by then is transfer the result files accumulated so far from where they now land (the so-called "data bridge") to the Storage Element at my Uni, so I can aggregate and analyse all the output files, and compare them to similar results produced by conventional means (i.e. normal GRID/CRAB3 jobs). This requires a lot of behind-the-scenes setting-up of trusted credentials. Luckily a colleague at Imperial College has the means and the (rusty) expertise to help in this; I hope to $DEITY it's completed early next week or I may not have the time for a full analysis. |
|
Send message Joined: 16 Aug 15 Posts: 967 Credit: 1,216,795 RAC: 0 |
What is the difference between CMS-dev and the other cern boinc projects(atlas, lhc)? I know, it is late, so, whenever you have the time... |
|
ivan Send message Joined: 20 Jan 15 Posts: 1156 Credit: 8,453,729 RAC: 298 |
What is the difference between CMS-dev and the other cern boinc projects(atlas, lhc)? Mainly, that we haven't been verified by the collaboration, and that some people in the Collaboration haven't even realised that we exist. And that we're not into an automatic production status -- I'm doing all the job creation and submission by myself, for example. Hopefully that will change soon, progress is being made on a few fronts. (Note that my role has expanded considerably from what I thought I'd signed up for...) So, if all goes well by the 15th I'll have concrete results to set before the Collaboration, and job submission will have moved to a more-sustainable model while result files will be able to be transferred under strict security control from the data-bridge to GRID storage. When that comes together, I'd hope to be able to declare a beta phase, and the project will move to a more unified framework being set up to encompass all LHC volunteer computing effort. Then we should be able to move quickly to set up CMS@Home proper, and invite volunteers from around the world to participate. I'd sort of like that to happen before I reach retirement age next year... Now, if you'll excuse me, I haven't started on this weekend's Guardian Prize crossword yet. |
|
Send message Joined: 9 Apr 15 Posts: 57 Credit: 230,221 RAC: 0 |
I did ask if I could break it... This is all down to mind-set isnt it. I once was working for a European manufacturer who had released a completely re-designed product and I was asked to test it. One of its innovations was a whole row of shiny buttons to switch through its operations. So I happily pushed all the buttons and after a few minutes everything stopped. It took a while to duplicate the error and then a day or so to find a fix for the controller so this type of error was removed. I sent my findings to the lab and got this returned: Problem: Your control problem Diagnosis: Your problem is not a Problem. Nobody would consider operating the controls in the manner you have suggested. |
|
tullio Send message Joined: 17 Aug 15 Posts: 62 Credit: 296,695 RAC: 0 |
I was working for Honeywell Information Systems Italy when it launched its first UNIX computer. We sent one to a technical journalist so that he could test it. The nest day he phoned: your computer does not work. But what have you done? we asked him. I typed "diskformat" he said. Out of the more 300 UNIX command he had chosen the only one that erased the disk. We eliminated that command. Tullio |
|
ivan Send message Joined: 20 Jan 15 Posts: 1156 Credit: 8,453,729 RAC: 298 |
I was working for Honeywell Information Systems Italy when it launched its first UNIX computer. We sent one to a technical journalist so that he could test it. The nest day he phoned: your computer does not work. But what have you done? we asked him. I typed "diskformat" he said. Out of the more 300 UNIX command he had chosen the only one that erased the disk. We eliminated that command. Well, obviously that's better than questioning his Italian machismo by popping up a confirmation, "Are you sure?" |
|
Send message Joined: 29 May 15 Posts: 162 Credit: 3,371,212 RAC: 10,273 |
How long is this time-out ? ... Two hours. Here is a stripe from a log from a normal BOINC-Session on my Desktop: 05/10/2015 16:43:20 | | Suspending computation - an exclusive app is running 05/10/2015 16:43:20 | | Suspending network activity - an exclusive app is running 05/10/2015 16:51:47 | ATLAS@home | update requested by user 05/10/2015 16:51:48 | ATLAS@home | Sending scheduler request: Requested by user. 05/10/2015 16:51:48 | ATLAS@home | Requesting new tasks for CPU 05/10/2015 16:51:50 | ATLAS@home | Scheduler request completed: got 0 new tasks 05/10/2015 16:51:50 | ATLAS@home | No tasks sent 05/10/2015 17:11:47 | ATLAS@home | update requested by user 05/10/2015 17:11:48 | ATLAS@home | Sending scheduler request: Requested by user. 05/10/2015 17:11:48 | ATLAS@home | Requesting new tasks for CPU 05/10/2015 17:11:50 | ATLAS@home | Scheduler request completed: got 0 new tasks 05/10/2015 17:11:50 | ATLAS@home | No tasks sent 05/10/2015 17:21:17 | | Resuming network activity 05/10/2015 17:22:23 | | Resuming computation 05/10/2015 17:22:26 | CMS-dev | [checkpoint] result CMS_8172_1427806845.384120_0 checkpointed 05/10/2015 17:22:26 | ATLAS@home | [checkpoint] result xnUMDmQVB3mnDDn7oo6G73TpABFKDmABFKDmoCNKDmABFKDmcAurXn_0 checkpointed 05/10/2015 17:22:26 | ATLAS@home | [checkpoint] result 6lhLDmiVD3mnDDn7oo6G73TpABFKDmABFKDmiSHKDmABFKDmE6a95n_0 checkpointed 05/10/2015 17:22:33 | | Suspending computation - CPU is busy 05/10/2015 17:23:06 | | Resuming computation 05/10/2015 17:23:27 | ATLAS@home | Sending scheduler request: To fetch work. 05/10/2015 17:23:27 | ATLAS@home | Requesting new tasks for CPU 05/10/2015 17:23:31 | ATLAS@home | Scheduler request completed: got 0 new tasks 05/10/2015 17:23:31 | ATLAS@home | No tasks sent 05/10/2015 17:26:21 | | Suspending computation - CPU is busy 05/10/2015 17:26:32 | | Resuming computation 05/10/2015 17:26:53 | | Suspending computation - CPU is busy 05/10/2015 17:27:03 | | Resuming computation 05/10/2015 17:27:25 | | Suspending computation - CPU is busy 05/10/2015 17:27:35 | | Resuming computation As you can see, a lot of things are done by BOINC to Keep my Workstation running well as a normal Desktop; These pauses are normal for BOINC-Users that have not exclusiv-crunching PCs. So, I think this collides with your timeout from 2 hours; no normal cruncher is Aware of this. What happens, if I come over your timeout ? My Client will continue crunching the outtimed WU, that is already given to another cruncher and waste crucnhing time or will it be aborted by the Condor (?) Queue ? You should consider adjusting the timeout to 12/24 hours Can jobs like these become the unknown error-jobs ? |
|
ivan Send message Joined: 20 Jan 15 Posts: 1156 Credit: 8,453,729 RAC: 298 |
What happens, if I come over your timeout ? My Client will continue crunching the outtimed WU, that is already given to another cruncher and waste crucnhing time or will it be aborted by the Condor (?) Queue ?It should move to the end of the queue and be re-sent when its time comes, unless it has been sent three times already. You should consider adjusting the timeout to 12/24 hoursOK, tell me if you see a difference from now on. Can jobs like these become the unknown error-jobs ?It's possible, but I don't think so; as far as I know Condor tells Dashboard when it re-schedules a job. |
|
Magic Quantum Mechanic Send message Joined: 8 Apr 15 Posts: 990 Credit: 17,725,241 RAC: 19,459 |
HTCondor 8.4.0 DAGMan |
|
ivan Send message Joined: 20 Jan 15 Posts: 1156 Credit: 8,453,729 RAC: 298 |
[Edit] I'll add a link to a graphic showing the command and data flow of CMS@Home when I get the chance, tho' it currently doesn't show how and where Dashboard hooks into it. It's not going to be easy to do from home so I might leave it for Monday afternoon or so.[/Edit] 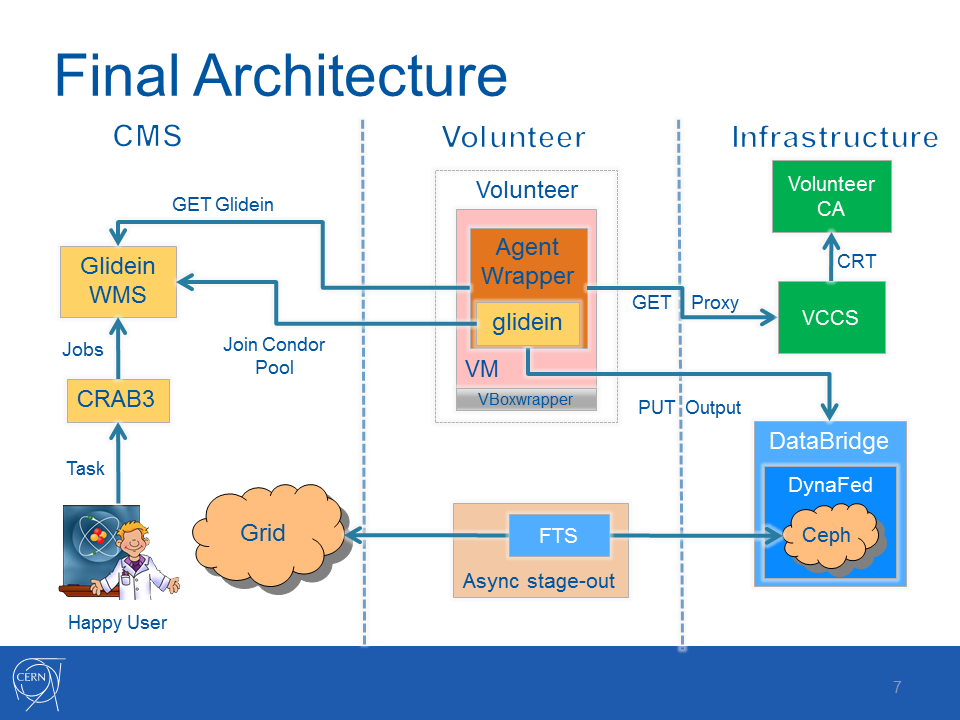 |
|
Magic Quantum Mechanic Send message Joined: 8 Apr 15 Posts: 990 Credit: 17,725,241 RAC: 19,459 |
DataBridge  |
|
Send message Joined: 29 May 15 Posts: 162 Credit: 3,371,212 RAC: 10,273 |
Are we out of Jobs ? |
|
ivan Send message Joined: 20 Jan 15 Posts: 1156 Credit: 8,453,729 RAC: 298 |
Are we out of Jobs ? No: http://boincai05.cern.ch/CMS-dev/cms_job.php -- around 2,000 to go in this batch. It's going to go past the seven-day default proxy certificate at about 1200 UTC tomorrow, but I've just worked out how to put in a new one; I'll try that tomorrow morning in case I do something wrong. |

©2026 CERN