Message boards : News : Jobs incoming!
Message board moderation
Previous · 1 . . . 4 · 5 · 6 · 7
| Author | Message |
|---|---|
 ivan ivanSend message Joined: 20 Jan 15 Posts: 1156 Credit: 8,453,729 RAC: 25 |
Maybe it would be a good idea to not download certain data again(that does not change) for every task/job, but store it locally. The idea of using CVMFS, etc, is that a good deal of caching does go on. We might see more of conditions database, etc, migrate from e.g. Frontier servers as the technology matures -- not everyone has CVMFS on their departmental machines (I'll be installing it as soon as I can get a Fujitsu disk caddy for a newly acquired 6 TB He-filled disk, I couldn't run a suggested workflow recently as it assumed data was available through CVMFS). As well, I just posted this to S@H: > On my Windows 10 PC I see lots of data going up to CERN programs such as > vLHC@home, Atlas@home and, especially, CMS-dev which is a Beta project. Yeah, I'm still tuning that of course. We had a computing meeting today which was a bit more positive than earlier in the year. Things are probably going to change in the submission method, but I don't think the volunteers will see a difference -- I'm hoping it will make my part easier, though. I'm also starting to get some reaction to my plea for consistent jobs with minimal data return, just don't expect it Real Soon Now. I'm trying to retrieve recent data so that I can compare it with normal GRID jobs and report at a meeting at CERN next month. With a bit of luck I can get a publicly-available report out of it, which should please the volunteers. (I realise this is more directed at CMS@Home, just reacting to tullio's comment.) (As a consequence of my broadband woes, I can't run CatH at home myself -- not enough capacity. :-( )  |
|
ivan Send message Joined: 20 Jan 15 Posts: 1156 Credit: 8,453,729 RAC: 25 |
New job batch coming soon! A bit snowed under today... |
|
ivan Send message Joined: 20 Jan 15 Posts: 1156 Credit: 8,453,729 RAC: 25 |
OK, we're running down this batch. For a bit of variety I'll go back to TTbar event generation, so the nature of the jobs will change when they start coming down the pipe. |
|
Send message Joined: 13 Feb 15 Posts: 1280 Credit: 1,047,486 RAC: 56 |
The variation of job duration of the first 391 jobs of this batch. Average 46 minutes MinTime 17 minutes MaxTime 273 minutes  |
|
ivan Send message Joined: 20 Jan 15 Posts: 1156 Credit: 8,453,729 RAC: 25 |
Seems reasonable. I fired up a task at home to see how it would cope -- my broadband has recently increased to 3 Mbps down/1 Mbps up. First job took a while, the rest are taking ~20 mins to calculate, ~30 mins overall. That's on a Core(TM) i7-4770K CPU @ 3.50GHz, also running six S@H CPU jobs and one S@H opencl job on a GTX 660 Ti (Linux Mint). [Later] Did you get that out of Dashboard or plot it yourself? There's lots of info in Dashboard (but as mentioned earlier, you need CMS credentials to see a lot of it and it's always out-of-date until some time after all jobs have finished). Here's an interesting graph -- the distribution of memory usage for the jobs (I presume per job rather than per event): 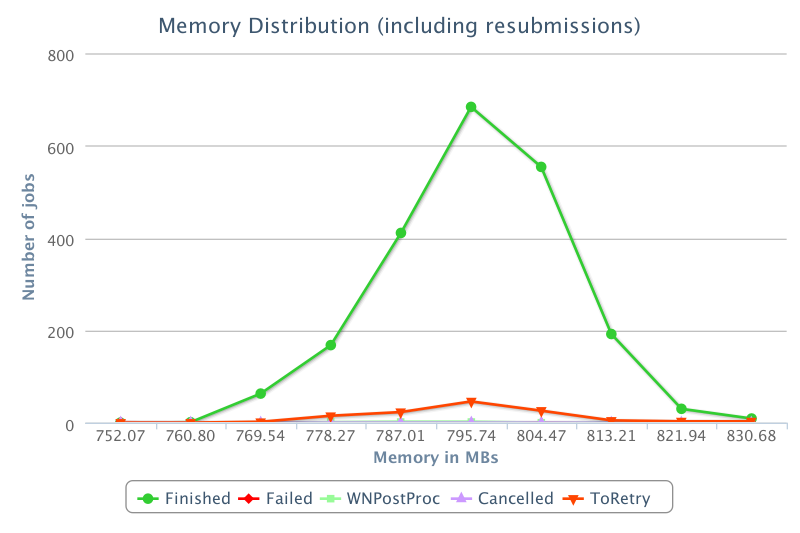 |
|
Send message Joined: 13 Feb 15 Posts: 1280 Credit: 1,047,486 RAC: 56 |
Did you get that out of Dashboard or plot it yourself? Yes, after some shuffling and filtering the dashboard info, I got that data from your last 151002_120226:ireid_crab_CMS_at_Home_TTbar18 - batch and put it in Excel. I used the first 391 successful tasks with a run time higher than 0 out of JobNumbers 1 to 400. |

©2026 CERN