Message boards : News : Jobs incoming!
Message board moderation
Previous · 1 · 2 · 3 · 4 · 5 · 6 · 7 · Next
| Author | Message |
|---|---|
 ivan ivanSend message Joined: 20 Jan 15 Posts: 1156 Credit: 8,453,729 RAC: 25 |
Hi Ivan, OK, it took me fart oo long to install a local copy of Condor, the version in the standard Scientific Linux CERN repository was too old; in the end I installed the very latest from rpm. So now I can get the number of running and available jobs remotely from the RAL machine. The question now is how to get them from here to the SSP? Ah! I just realised that this isn't really the number of available jobs, as Condor only holds ~1000 jobs in its (visible) queue, so if we get this working you'll never see much more than 1000 available, but you would see when the number starts falling below 1000. After a bit of playing around: [eesridr:src] > . stats Tue Sep 8 14:32:57 UTC 2015: 64 running, 168 idle  |
|
Send message Joined: 16 Aug 15 Posts: 967 Credit: 1,216,795 RAC: 0 |
That is great! Thanks for your effort. At least there would be an indication, when jobs are going to run out. |
|
Send message Joined: 16 Aug 15 Posts: 967 Credit: 1,216,795 RAC: 0 |
I think, i know now why there are missing run-folders. cron-stdout: 16:25:01 +0200 2015-09-08 [INFO] Starting CMS Application - Run 1 16:25:01 +0200 2015-09-08 [INFO] Reading the BOINC volunteer's information 16:25:02 +0200 2015-09-08 [INFO] Volunteer: Rasputin42 (277) Host: 617 16:25:02 +0200 2015-09-08 [INFO] VMID: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx 16:25:02 +0200 2015-09-08 [INFO] Requesting an X509 credential 16:25:05 +0200 2015-09-08 [ERROR] Proxy error 16:25:05 +0200 2015-09-08 [INFO] Going to sleep for 1 hour 16:26:01 +0200 2015-09-08 [INFO] Starting CMS Application - Run 2 16:26:01 +0200 2015-09-08 [INFO] Reading the BOINC volunteer's information 16:26:02 +0200 2015-09-08 [INFO] Volunteer: Rasputin42 (277) Host: 617 16:26:02 +0200 2015-09-08 [INFO] VMID: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx 16:26:02 +0200 2015-09-08 [INFO] Requesting an X509 credential subject : /O=Volunteer Computing/O=CERN/CN=Rasputin42 277/CN=803544860 issuer : /O=Volunteer Computing/O=CERN/CN=Rasputin42 277 identity : /O=Volunteer Computing/O=CERN/CN=Rasputin42 277 type : RFC 3820 compliant impersonation proxy strength : 1024 bits path : /tmp/x509up_u500 timeleft : 129:59:01 (5.4 days) 16:26:03 +0200 2015-09-08 [INFO] Downloading glidein 16:26:06 +0200 2015-09-08 [INFO] Running glidein (check logs) cron-sterr: chmod: cannot access `/tmp/x509up_u500': No such file or directory ERROR: Couldn't find a valid proxy. globus_sysconfig: Could not find a valid proxy certificate file location globus_sysconfig: Error with key filename globus_sysconfig: File does not exist: /tmp/x509up_u500 is not a valid file Use -debug for further information. This is similar to the error that was reported before. |
|
PDW Send message Joined: 20 May 15 Posts: 217 Credit: 6,294,052 RAC: 0 |
I think, i know now why ther are missing run-folders. So it isn't just me getting these errors then ! |
|
Send message Joined: 16 Aug 15 Posts: 967 Credit: 1,216,795 RAC: 0 |
Apparently not. However, in my case, it recovers immediately. |
|
Send message Joined: 20 Mar 15 Posts: 243 Credit: 901,716 RAC: 0 |
Took a quick look at a host here, seems to work first time so perhaps a timing problem somewhere. 17:02:03 +0100 2015-09-08 [INFO] CMS glidein Run 0 ended 17:03:01 +0100 2015-09-08 [INFO] Starting CMS Application - Run 1 17:03:01 +0100 2015-09-08 [INFO] Reading the BOINC volunteer's information 17:03:05 +0100 2015-09-08 [INFO] Volunteer: m (178) Host: 243 17:03:05 +0100 2015-09-08 [INFO] VMID: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx 17:03:05 +0100 2015-09-08 [INFO] Requesting an X509 credential subject : /O=Volunteer Computing/O=CERN/CN=m 178/CN=2116421106 issuer : /O=Volunteer Computing/O=CERN/CN=m 178 identity : /O=Volunteer Computing/O=CERN/CN=m 178 type : RFC 3820 compliant impersonation proxy strength : 1024 bits path : /tmp/x509up_u500 timeleft : 129:59:58 (5.4 days) 17:03:13 +0100 2015-09-08 [INFO] Downloading glidein 17:03:20 +0100 2015-09-08 [INFO] Running glidein (check logs) |
|
ivan Send message Joined: 20 Jan 15 Posts: 1156 Credit: 8,453,729 RAC: 25 |
That is great! Thanks for your effort. Yeah, there are a couple of air-gaps/firewalls that I can't see my way though just yet, so don't hold your breath too long. :-/ |
|
Send message Joined: 16 Aug 15 Posts: 967 Credit: 1,216,795 RAC: 0 |
Do you(or anyone else) have any missing run-x folders on any of your hosts? run-1, run-2, run-4....... x |
|
Send message Joined: 20 Mar 15 Posts: 243 Credit: 901,716 RAC: 0 |
The short answer is no. But the hosts here run overnight and are switched off during the day. Although the directory structure does appear to be preserved it may not be typical. I started one manually to look at this, only run-1 and run-2 so far. However it's spent the last hour trying in vain to get another CMS job, Edit.Went to turn it off, only to find it working away so it's been reprieved for now. |
|
Send message Joined: 13 Feb 15 Posts: 1281 Credit: 1,047,486 RAC: 56 |
Do you(or anyone else) have any missing run-x folders on any of your hosts? Yeah, never seen this, but when you're asking: it happens ;) Map run-1 not created. First map is run-2/ Contents of cron-stdout: 20:43:01 +0200 2015-09-08 [INFO] Starting CMS Application - Run 1 20:43:01 +0200 2015-09-08 [INFO] Reading the BOINC volunteer's information 20:43:02 +0200 2015-09-08 [INFO] Volunteer: Crystal Pellet (38) Host: 37 20:43:02 +0200 2015-09-08 [INFO] VMID: a248a608-bb13-4ecc-8fba-70015f0a4b90 20:43:02 +0200 2015-09-08 [INFO] Requesting an X509 credential 20:43:05 +0200 2015-09-08 [ERROR] Proxy error 20:43:05 +0200 2015-09-08 [INFO] Going to sleep for 1 hour 20:44:01 +0200 2015-09-08 [INFO] Starting CMS Application - Run 2 20:44:01 +0200 2015-09-08 [INFO] Reading the BOINC volunteer's information 20:44:02 +0200 2015-09-08 [INFO] Volunteer: Crystal Pellet (38) Host: 37 20:44:02 +0200 2015-09-08 [INFO] VMID: a248a608-bb13-4ecc-8fba-70015f0a4b90 20:44:02 +0200 2015-09-08 [INFO] Requesting an X509 credential subject : /O=Volunteer Computing/O=CERN/CN=CrystalPellet 38/CN=1660116057 issuer : /O=Volunteer Computing/O=CERN/CN=CrystalPellet 38 identity : /O=Volunteer Computing/O=CERN/CN=CrystalPellet 38 type : RFC 3820 compliant impersonation proxy strength : 1024 bits path : /tmp/x509up_u500 timeleft : 130:00:00 (5.4 days) 20:44:04 +0200 2015-09-08 [INFO] Downloading glidein 20:44:08 +0200 2015-09-08 [INFO] Running glidein (check logs) Sleeping for 1 hour is 1 minute. |
|
PDW Send message Joined: 20 May 15 Posts: 217 Credit: 6,294,052 RAC: 0 |
Well it's nice to know it isn't just happening to me but at least all of your systems seem to be able to recover and eventually get a credential. Once mine fail they don't recover, I've tried turning both the router and modem off today but not as long as I did on Saturday when I first noticed it. Neither of these actions had any effect so at the moment I have suspended them :-( |
|
ivan Send message Joined: 20 Jan 15 Posts: 1156 Credit: 8,453,729 RAC: 25 |
TI started one manually to look at this, only run-1 and run-2 so far. However Heh! We were running out of the batch I submitted yesterday (1000x 250-event MinBias jobs), so I submitted another 10,000 late this afternoon. I think that'll keep you busy for a week or so! I'm off to a UK GRIDPP meeting tomorrow for the rest of the week (I decided not to go to the CMS Week in Ischia this week, Italian food is so boring...), so you may not hear too much from me until Saturday. (I might be up early Saturday, landscapers are coming to clear the jungle that I laughingly call my garden, and they have petrol-powered implements of destruction...) |
|
Send message Joined: 16 Aug 15 Posts: 967 Credit: 1,216,795 RAC: 0 |
Events are very short. A lot of them are only a few seconds long (3-9 per minute)!!! Is that OK? |
|
ivan Send message Joined: 20 Jan 15 Posts: 1156 Credit: 8,453,729 RAC: 25 |
Events are very short. A lot of them are only a few seconds long (3-9 per minute)!!! Yes, they are minimal interactions with the occasional chance of something more complex. Though it sounds as if you have a reasonably fast processor... |
|
ivan Send message Joined: 20 Jan 15 Posts: 1156 Credit: 8,453,729 RAC: 25 |
This batch of jobs is coming to a close soon: Tue Sep 15 20:20:01 UTC 2015: 66 running, 833 idle(Oh, Laurence is looking into whether we can get that info onto the Status Page.) I'll submit another lot tomorrow with fewer events, to see if that affects the number of jobs that don't report results -- we may be reaching a limit on the practical size of result files. [Later] Actually, that status may be misleading, there may be other jobs in the queue too -- Dashboard thinks there are still 5,000 jobs to run. I've fewer than 6,000 results returned and delving into the Condor status I see: [cms005@lcggwms02:~] > grep STATUS_READY 150908_152652:ireid_crab_CMS_at_Home_MinBias2/node_state.txt|wc 4380 26280 170820 Tue Sep 15 21:51:25 [cms005@lcggwms02:~] > grep STATUS_DONE 150908_152652:ireid_crab_CMS_at_Home_MinBias2/node_state.txt|wc 4315 25890 163970 Tue Sep 15 21:51:40 [cms005@lcggwms02:~] > grep STATUS_ERROR 150908_152652:ireid_crab_CMS_at_Home_MinBias2/node_state.txt|wc 422 2532 16458 Tue Sep 15 21:51:44 [cms005@lcggwms02:~] > grep STATUS_PRERUN 150908_152652:ireid_crab_CMS_at_Home_MinBias2/node_state.txt|wc 0 0 0 Tue Sep 15 21:52:12 [cms005@lcggwms02:~] > grep STATUS_SUBMITTED 150908_152652:ireid_crab_CMS_at_Home_MinBias2/node_state.txt|wc 884 5305 38014 Tue Sep 15 21:52:28 [cms005@lcggwms02:~] > grep STATUS_POSTRUN 150908_152652:ireid_crab_CMS_at_Home_MinBias2/node_state.txt|wc 1 6 41 To be investigated tomorrow... |
|
PDW Send message Joined: 20 May 15 Posts: 217 Credit: 6,294,052 RAC: 0 |
Roughly 10% error rate doesn't look good, do you know what's causing that ? |
|
ivan Send message Joined: 20 Jan 15 Posts: 1156 Credit: 8,453,729 RAC: 25 |
Roughly 10% error rate doesn't look good, do you know what's causing that ? I suspect it's the larger result-file size, which should show up soon enough when I halve the size of the jobs (could be the longer run time leading to more losses on suspend/resume too). At the moment I'm more puzzled at the discrepancy between the Condor queue reports and the actual returned results. |
|
ivan Send message Joined: 20 Jan 15 Posts: 1156 Credit: 8,453,729 RAC: 25 |
Hmm, this doesn't look good! 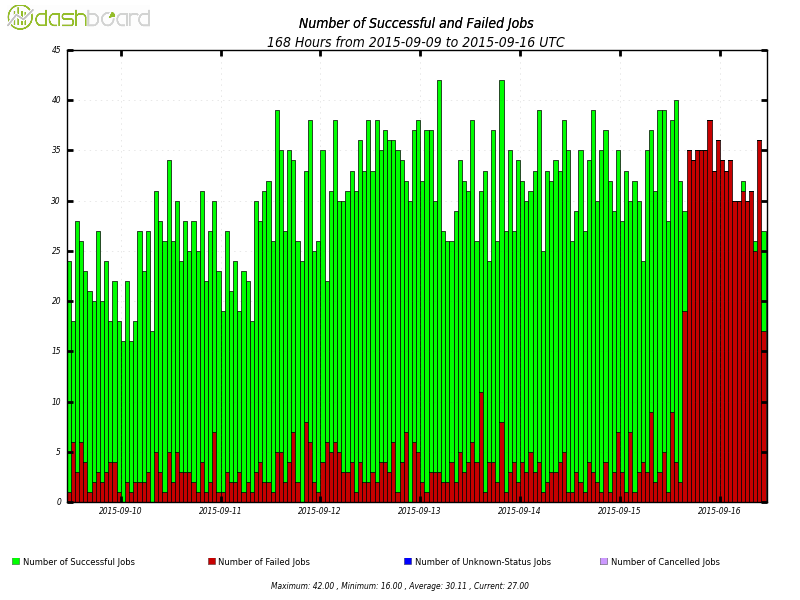 Lots of jobs failing after two retries. |
Laurence CERN Send message Joined: 12 Sep 14 Posts: 1161 Credit: 342,328 RAC: 0 |
Looking at the logs of my last job, everything seems fine (exit status 0). Might be something on the Condor server. |
|
Send message Joined: 13 Feb 15 Posts: 1281 Credit: 1,047,486 RAC: 56 |
This batch of jobs is coming to a close soon: I've job 5850 running out of the 10,000 you announced last week. So I'm guessing why you think we're soon to a close. Are there future jobs purged from the queue? |

©2026 CERN