Message boards : News : Jobs incoming!
Message board moderation
Previous · 1 . . . 3 · 4 · 5 · 6 · 7 · Next
| Author | Message |
|---|---|
 PDW PDWSend message Joined: 20 May 15 Posts: 217 Credit: 6,294,052 RAC: 0 |
Mine seem to be running normally, haven't noticed anything wrong. In fact since about the 11th I haven't seen an X509 error and I am no longer jumping time zones. Don't know whether my ISP did something, you did something or it's just the direction the rain is falling that makes everything work now ! |
|
Send message Joined: 20 Mar 15 Posts: 243 Credit: 901,716 RAC: 0 |
Started a host manually to see if anything seems wrong. Watched job 5856 all the way through. 250 events no problems. "Complete process id is 8212 status is 0" I suppose there could be a problem sending the result back, how would we know? Edit:- This is from condor stdout... INFO Davix: Operation failure: HTTP 404 : File not found . After 1 retry INFO Davix: Failure: Impossible to execute operation on https://data-bridge-test.cern.ch/myfed/cms-boinc/output//dpm/brunel.ac.uk/home/cms/store/user/ireid/CMS_at_Home/CRAB3_MinBias/150908_152652/0005/step1_5856.root, error Failure HTTP 404 : File not found after 1 attempts INFO Davix: Try to Recover with Metalink... DEBUG Davix: Creat HttpRequest for https://data-bridge-test.cern.ch/myfed/cms-boinc/output//dpm/brunel.ac.uk/home/cms/store/user/ireid/CMS_at_Home/CRAB3_MinBias/150908_152652/0005/step1_5856.root DEBUG Davix: Executing head query to https://data-bridge-test.cern.ch/myfed/cms-boinc/output//dpm/brunel.ac.uk/home/cms/store/user/ireid/CMS_at_Home/CRAB3_MinBias/150908_152652/0005/step1_5856.root for Metalink file Does this indicate a problem? if this:- output//dpm/brunel.ac.uk/ is part of a pathname, should there be "//" there? or do others have as much trouble typing as I do. |
|
ivan Send message Joined: 20 Jan 15 Posts: 1156 Credit: 8,453,729 RAC: 25 |
Does this indicate a problem? if this:- Thanks for the output, not too sure yet what the problem is, I'll get my VM running again. A double slash in a Linux pathname is no problem as far as I'm aware.  |
|
Send message Joined: 29 May 15 Posts: 163 Credit: 3,582,465 RAC: 8,980 |
Are still all incoming Jobs are bad ? Mine may have been bad until 11:00 °Clock this morning (my Squid was hanging), but since then, it seems as if all is running fine. |
|
ivan Send message Joined: 20 Jan 15 Posts: 1156 Credit: 8,453,729 RAC: 25 |
I get the same for a job I know was successful: INFO Davix: Failure: Impossible to execute operation on https://data-bridge-test.cern.ch/myfed/cms-boinc/output//dpm/brunel.ac.uk/home/cms/store/user/ireid/CMS_at_Home/CRAB3_MinBias/150908_152652/0000/step1_6.root, error Failure HTTP 404 : File not found after 1 attempts INFO Davix: Try to Recover with Metalink... DEBUG Davix: Creat HttpRequest for https://data-bridge-test.cern.ch/myfed/cms-boinc/output//dpm/brunel.ac.uk/home/cms/store/user/ireid/CMS_at_Home/CRAB3_MinBias/150908_152652/0000/step1_6.root DEBUG Davix: Executing head query to https://data-bridge-test.cern.ch/myfed/cms-boinc/output//dpm/brunel.ac.uk/home/cms/store/user/ireid/CMS_at_Home/CRAB3_MinBias/150908_152652/0000/step1_6.root for Metalink file Now, let's look at 5856: job_out.5856.0.txt on the Condor server looks OK, but unfortunately Dashboard has it as "pending". Ah! But there's a job_out.5856.1.txt as well, so it's been resubmitted: cat 150908_152652:ireid_crab_CMS_at_Home_MinBias2/job_out.5856.1.txt Job output has not been processed by post-job. So, something's giving the same symptoms we had a few weeks ago. :-( |
|
ivan Send message Joined: 20 Jan 15 Posts: 1156 Credit: 8,453,729 RAC: 25 |
Are still all incoming Jobs are bad ? See above; jobs aren't reporting as successful to Condor and Dashboard. Ah, Bingo! Job 5856 has returned a result, so the problem's at the Condor end. |
|
ivan Send message Joined: 20 Jan 15 Posts: 1156 Credit: 8,453,729 RAC: 25 |
Problem solved, we think. Turns out that Condor uses a different proxy than the one I renew periodically at work, and it had a default life of seven days. Which expired... I've put in a small batch of jobs half as big as the last batch, which should get us through the night until I can sort out the base problem tomorrow. By the way, check out a new Job Activities Page. Thanks to Andrew and Laurence for that one. |
|
PDW Send message Joined: 20 May 15 Posts: 217 Credit: 6,294,052 RAC: 0 |
Hurray. Like the new JAP, any chance of a link on the left for it ? |
|
PDW Send message Joined: 20 May 15 Posts: 217 Credit: 6,294,052 RAC: 0 |
Guessing the error rate has dropped significantly then ? |
|
ivan Send message Joined: 20 Jan 15 Posts: 1156 Credit: 8,453,729 RAC: 25 |
Guessing the error rate has dropped significantly then ? Early days, but Dashboard reckons 57 successes and no failures so far with the new batch. |
|
ivan Send message Joined: 20 Jan 15 Posts: 1156 Credit: 8,453,729 RAC: 25 |
Hurray. I understand that Laurence is brushing up on his PHP... |
|
ivan Send message Joined: 20 Jan 15 Posts: 1156 Credit: 8,453,729 RAC: 25 |
Guessing the error rate has dropped significantly then ? This is looking better now: 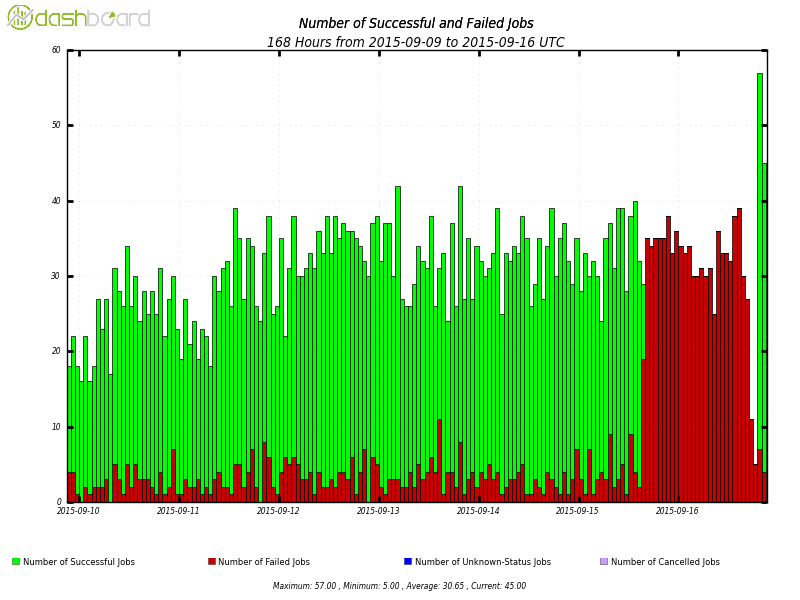 |
|
PDW Send message Joined: 20 May 15 Posts: 217 Credit: 6,294,052 RAC: 0 |
Hurray. :-) |
|
Send message Joined: 29 May 15 Posts: 163 Credit: 3,582,465 RAC: 8,980 |
Just found: 09/17/15 19:48:54 (pid:12496) attempt to connect to <130.246.180.120:9619> failed: timed out after 20 seconds. 09/17/15 19:48:54 (pid:12496) ERROR: SECMAN:2003:TCP connection to collector lcggwms02.gridpp.rl.ac.uk:9619 failed. 09/17/15 19:48:54 (pid:12496) Failed to start non-blocking update to <130.246.180.120:9619>. 09/17/15 19:49:30 (pid:12496) attempt to connect to <130.246.180.120:9619> failed: Connection timed out (connect errno = 110). 09/17/15 19:49:30 (pid:12496) ERROR: SECMAN:2003:TCP connection to collector lcggwms02.gridpp.rl.ac.uk:9619 failed. 09/17/15 19:49:30 (pid:12496) CCBListener: connection to CCB server lcggwms02.gridpp.rl.ac.uk:9619 failed; will try to reconnect in 60 seconds. 09/17/15 19:52:37 (pid:12496) attempt to connect to <130.246.180.120:9619> failed: Connection timed out (connect errno = 110). Will keep trying for 300 total seconds (173 to go). I checked my Firewall and found, that until now only ports 9620-9623 are opened for CMS. Now I added 9619. It would really be very helpfull if someone could check which ports are needed for which IP-Adress(es). http://boincai05.cern.ch/CMS-dev/forum_thread.php?id=63 |
|
ivan Send message Joined: 20 Jan 15 Posts: 1156 Credit: 8,453,729 RAC: 25 |
I've alerted some experts to check it out -- way beyond me, I'm afraid. |
|
Magic Quantum Mechanic Send message Joined: 8 Apr 15 Posts: 1005 Credit: 18,286,918 RAC: 22,723 |
No problems here. Mad Scientist For Life 
|
|
Send message Joined: 13 Feb 15 Posts: 1281 Credit: 1,047,486 RAC: 56 |
I've put in a small batch of jobs half as big as the last batch, which should get us through the night until I can sort out the base problem tomorrow. Positive side effect. The number of failed jobs is about the same as before condor striked, but by halving the numbers of events per job, the number of jobs is doubled. So the percentage of failed jobs is halved. |
|
Send message Joined: 20 Mar 15 Posts: 243 Credit: 901,716 RAC: 0 |
Hurray. Yes!!! Thanks, Laurence. All it needs now, to be really useful is to be able to see the numbers of good/failed/abandoned jobs per host... |
|
Send message Joined: 20 Mar 15 Posts: 243 Credit: 901,716 RAC: 0 |
I've put in a small batch of jobs half as big as the last batch, which should get us through the night until I can sort out the base problem tomorrow. Since the overheads for this project seem quite high (don't know about Atlas, we aren't allowed to see what's going on inside there...) there will be a point at which they cause the throughput to decrease again as the size of jobs is reduced. It would be nice to see where this point is. |
|
Send message Joined: 16 Aug 15 Posts: 967 Credit: 1,216,795 RAC: 0 |
Maybe it would be a good idea to not download certain data again(that does not change) for every task/job, but store it locally. I would also like to know the benefits of constant network connection versus the download, crunch, upload approach. |

©2026 CERN