Message boards : News : Jobs incoming!
Message board moderation
Previous · 1 · 2 · 3 · 4 · 5 · 6 . . . 7 · Next
| Author | Message |
|---|---|
 ivan ivanSend message Joined: 20 Jan 15 Posts: 1156 Credit: 8,453,729 RAC: 25 |
When new patches from Microsoft come in (or some other reason to restart a machine), I'm looking for a good Point to restart the Client. Probably a bit earlier than that, but I haven't studied the sequence in full. As you already know, suspend/resume is not our strong point. Providing you're not doing it every day (or more often!) I don't think the project really cares that much -- not at the moment, anyway. Myself, I usually set "No new tasks" and wait until the current task times out.  |
|
Send message Joined: 29 May 15 Posts: 163 Credit: 3,581,188 RAC: 9,012 |
Myself, I usually set "No new tasks" and wait until the current task times out. I would love to set "No new Tasks" to inside the VM so that it doesn't fetch more Jobs. Perhaps a Point for the ToDo-List later on if this Project survives ;-) |
Laurence CERN Send message Joined: 12 Sep 14 Posts: 1161 Credit: 342,328 RAC: 0 |
Should be easy. We can add a button in the graphics web app that sets a shutdown signal. When the job finishes it will shutdown the VM rather than run another job. |
|
Send message Joined: 29 May 15 Posts: 163 Credit: 3,581,188 RAC: 9,012 |
Should be easy. We can add a button in the graphics web app that sets a shutdown signal. When the job finishes it will shutdown the VM rather than run another job. Yeah, I would love this |
|
Send message Joined: 16 Aug 15 Posts: 967 Credit: 1,216,795 RAC: 0 |
I know, you have other things to do, but if you find the time----? Is there a way to improve efficiency? Currently the vboxheadless process has only an overall utilization of 88%.(24h) This includes a lot of overhead. (atlas is in the mid 90%) Would it be possible to have the "uploading" and "downloading" running in the background and at the same time the cpu crunching ? There seems to be a lot of fruitless cpu idling going on. According to my conservative estimates, it should be possible to double the output. |
|
ivan Send message Joined: 20 Jan 15 Posts: 1156 Credit: 8,453,729 RAC: 25 |
I've started a thread in Number Crunching to allow people to set out ideas for improvements. Please make your suggestions there, but move discussions to a parallel thread to try to keep the wish-list uncluttered. Cheers, ivan. |
|
ivan Send message Joined: 20 Jan 15 Posts: 1156 Credit: 8,453,729 RAC: 25 |
I know, you have other things to do, but if you find the time----? We could run longer jobs, so the startup phase takes up proportionately less time, but then the output files would be larger and we run the risk of communication time-outs in staging out the results. This apparently happened when I tried to send larger jobs a couple of weeks ago, so I'm loth to produce output much larger than the current 30-35 MB. This could vary with the type of simulation being run, too. I'll try again tomorrow to get my colleagues to suggest interesting jobs to run, my repertoire is rather limited. |
|
Send message Joined: 16 Aug 15 Posts: 967 Credit: 1,216,795 RAC: 0 |
Thanks, Ivan. First you have to get it running reliably at all, then optimize. I understand. |
|
Send message Joined: 29 May 15 Posts: 163 Credit: 3,581,188 RAC: 9,012 |
We could run longer jobs, so the startup phase takes up proportionately less time, but then the output files would be larger and we run the risk of communication time-outs in staging out the results. This apparently happened when I tried to send larger jobs a couple of weeks ago, so I'm loth to produce output much larger than the current 30-35 MB. You could make it configurable for the user, if (s)he has a stable Internet or not (e.g. my vDSL has 50 MBit down- and 10 MBit upload) |
|
Send message Joined: 13 Feb 15 Posts: 1281 Credit: 1,047,486 RAC: 56 |
Cause it happened during this run of jobs, I post it here. I have 1 cmsRun, that did not ended normally; up to 21st record thereafter nothing more reported. Meanwhile another cmsRun has ended normally and another new one is running. Do you want to have some logs from this unfinished cmsRun? I've extended the BOINC-runtime to 40 hours (atm 24 hrs), so will be able to post (or email) the logs tomorrow. |
|
ivan Send message Joined: 20 Jan 15 Posts: 1156 Credit: 8,453,729 RAC: 25 |
We could run longer jobs, so the startup phase takes up proportionately less time, but then the output files would be larger and we run the risk of communication time-outs in staging out the results. This apparently happened when I tried to send larger jobs a couple of weeks ago, so I'm loth to produce output much larger than the current 30-35 MB. Sucks to be you :-0! Here's my connexion tonight: Connection mode : ADSL2 Type : Fast Noise margin (dB) : 12.3 Attenuation (dB) : 46.0 Attainable download rate (kbps) : 2224 ADSL status : Connected [0] Downstream Upstream Rate (kbps) 1148 1077 But that apart, the size of the jobs is determined at submission time for the batch concerned, it's not configurable on a job-by-job basis. Sorry... |
|
ivan Send message Joined: 20 Jan 15 Posts: 1156 Credit: 8,453,729 RAC: 25 |
Looks like this batch will run out tonight at this rate (i.e. another 4 or 5 jobs for each machine) so tomorrow I'll have the timing statistics I want for my comparison: Well, it just made midnight, London time: 97 jobs; 0 completed, 0 removed, 0 idle, 82 running, 15 held, 0 suspendedso I submitted another 1,000 jobs the same as the last batch. That lasted a bit over 30 hours; hopefully this lot will get us into next week. Statistics? Who needs 'em? [Update] All jobs now submitted to the Condor queue and updated with the required constraints. I'm for bed, after attempting today's Guardian cryptic crossword... [/Update] |
|
Send message Joined: 13 Feb 15 Posts: 1281 Credit: 1,047,486 RAC: 56 |
I have 1 cmsRun, that did not ended normally; up to 21st record thereafter nothing more reported. Could following (from MasterLog) has been the reason? 09/01/15 21:32:19 (pid:9715) CCBListener: no activity from CCB server in 1240s; assuming connection is dead. 09/01/15 21:32:19 (pid:9715) CCBListener: connection to CCB server lcggwms02.gridpp.rl.ac.uk:9621 failed; will try to reconnect in 60 seconds. 09/01/15 21:32:38 (pid:9715) DefaultReaper unexpectedly called on pid 9718, status 25344. 09/01/15 21:32:38 (pid:9715) The STARTD (pid 9718) exited with status 99 (daemon will not restart automatically) 09/01/15 21:33:19 (pid:9715) CCBListener: registered with CCB server lcggwms02.gridpp.rl.ac.uk:9621 as ccbid 130.246.180.120:9621#52528 09/01/15 21:37:44 (pid:9715) The DaemonShutdown expression "(STARTD_StartTime =?= 0)" evaluated to TRUE: starting graceful shutdown 09/01/15 21:37:44 (pid:9715) Got SIGTERM. Performing graceful shutdown. 09/01/15 21:37:44 (pid:9715) All daemons are gone. Exiting. 09/01/15 21:37:44 (pid:9715) **** condor_master (condor_MASTER) pid 9715 EXITING WITH STATUS 99 |
|
Send message Joined: 9 Apr 15 Posts: 57 Credit: 230,221 RAC: 0 |
Dunno whats happening here - I have two machines with jobs whizzing through for the last 2 days (hope they're giving good results)... |
|
Send message Joined: 13 Feb 15 Posts: 1281 Credit: 1,047,486 RAC: 56 |
... so I submitted another 1,000 jobs the same as the last batch. That lasted a bit over 30 hours; hopefully this lot will get us into next week. Not sure, but guessing less than 290 jobs left. Short weeks in Britain ;) |
|
ivan Send message Joined: 20 Jan 15 Posts: 1156 Credit: 8,453,729 RAC: 25 |
... so I submitted another 1,000 jobs the same as the last batch. That lasted a bit over 30 hours; hopefully this lot will get us into next week. Typo; 10,000 jobs... |
|
ivan Send message Joined: 20 Jan 15 Posts: 1156 Credit: 8,453,729 RAC: 25 |
FYI, here are graphs showing how long it took to get jobs back from the Grid and from CMS@Home from that batch of 2,000 jobs on Monday: 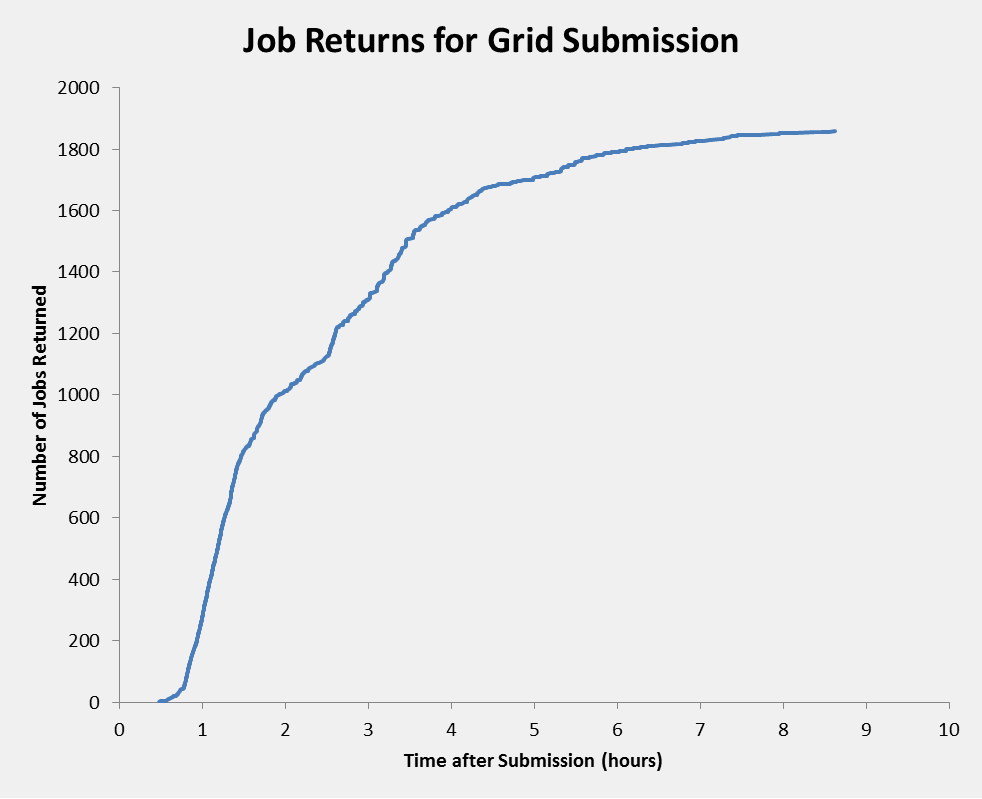 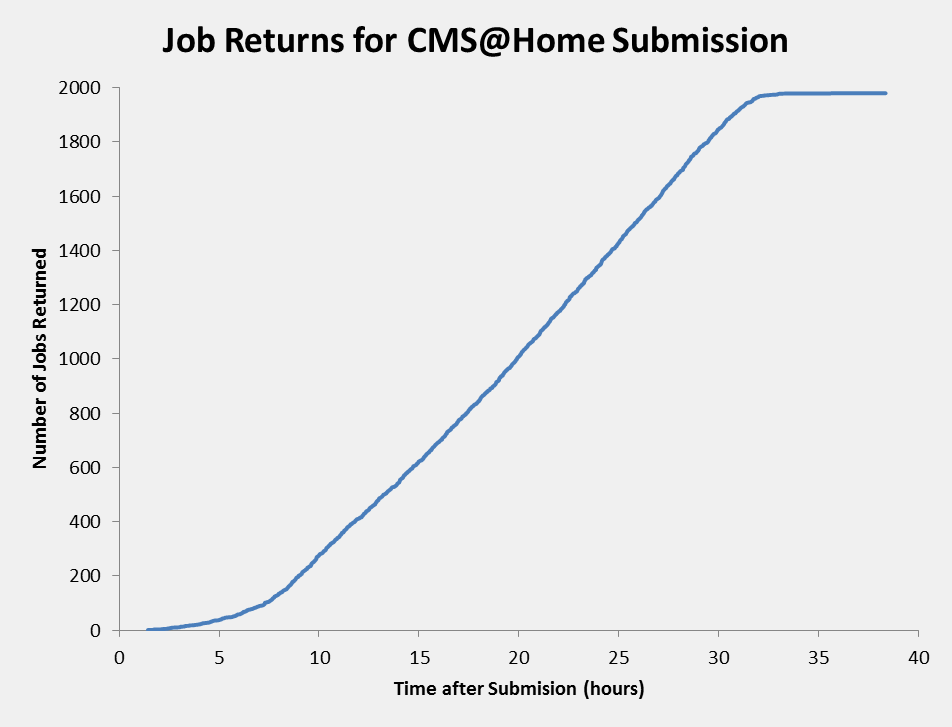 and active jobs since Monday on T3_CH_Volunteer (time scale goes until midnight tonight, it wasn't obvious how to set it to "now"):  |
|
Send message Joined: 20 Mar 15 Posts: 243 Credit: 901,716 RAC: 0 |
Thanks,Ivan. Very interesting. Certainly shows we aren't the fastest. Surprise, surprise although it's better than I, for one, expected, given all the inefficiencies in the present system. Production work, when the volunteers aren't as involved might not be quite so good although there will be more machines. Is there a "Grid" version of the last plot, failed/successful jobs? Where are the "lost" (abandoned) jobs in these statistics? Can they be shown separately? As vLHC do? (I think)second plot down |
|
ivan Send message Joined: 20 Jan 15 Posts: 1156 Credit: 8,453,729 RAC: 25 |
Thanks,Ivan. There is probably at least one way of dredging up those statistics, but Dashboard is such a huge thing with far too many options. The other problem is that we're not as tightly coupled to the reporting as Grid might be, and lots of things can go astray. OTOH, Dashboard reported 1970 successes for the Grid batch, but I only counted 1858 returned results, [As usual, I got dragged away by other things and forgot to post this.] |
|
Send message Joined: 29 May 15 Posts: 163 Credit: 3,581,188 RAC: 9,012 |
Seems as if Microsoft doesn't like your app. On Tuesday they had patches that needed restarts, today they had one patch but it needs a restart too :-( Not good for the Performance of your app |

©2026 CERN