|
1)
Message boards :
News :
No new jobs
(Message 1149)
Posted 1 Oct 2015 by Richard Haselgrove Post: automagically It's been in use at SETI since at least August 2004, which was the test phase of their conversion to BOINC. So you may have caught it from someone else... |
|
2)
Message boards :
Number crunching :
Issue of the day - 5th September 2015
(Message 1077)
Posted 9 Sep 2015 by Richard Haselgrove Post: The last thing in boot.log is Activating Fuse module. That's the last line in my boot.log too. Tue Sep 8 21:38:23 2015: cms.cern.ch: Activating Fuse module The next step seems to be at the start of cron-stdout 21:39:01 +0100 2015-09-08 [INFO] Starting CMS Application - Run 1 and so on - this task went on to create four run-x folders and processed an uncounted number of events. |
|
3)
Message boards :
Number crunching :
vboxwrapper issue
(Message 1075)
Posted 9 Sep 2015 by Richard Haselgrove Post: I thought I had converted the log extraction over to using the COM API when running on Windows. Someone else will have to answer that one - any 'nixers out there able to comment? |
|
4)
Message boards :
Number crunching :
vboxwrapper issue
(Message 1074)
Posted 9 Sep 2015 by Richard Haselgrove Post: There was a discussion about this on the boinc_alpha email last week. Jacob Klein started that conversation last Wednesday (2nd September), because he saw the same heavy disk usage at RNA World. First of all, somebody - probably Rom Walton - would have to code the change, and there's no sign of that yet. Rom is no longer a paid employee of BOINC (since the BOINC project failed to get renewal of their NSF grant funding in the summer), and is coding as a volunteer in his spare time. With last weekend being the Labor Day holiday in the USA, I don't blame him taking a break. Compiled wrappers are usually available for downloading soon after coding, but I imagine projects using them would want a period of in-house testing before deploying them for general use. There is a wrapper v26170 already - one newer than we use here - but that was compiled on 25 August, so it won't have this fix. |
|
5)
Message boards :
Number crunching :
vboxwrapper issue
(Message 1068)
Posted 9 Sep 2015 by Richard Haselgrove Post: There was a discussion about this on the boinc_alpha email last week. Selected extracts: David Anderson wrote Rom Walton wrote Rom again So, maybe the next version of the wrapper? |
|
6)
Message boards :
Number crunching :
Multiple Jobs In A Single Host
(Message 1003)
Posted 5 Sep 2015 by Richard Haselgrove Post: Note that there is a "bug" in that whilst the app_config file will allow only one task to run at a time, the work fetch process doesn't take this into account. So more tasks can be downloaded only for the "excess" to sit there waiting. This can also result in idle cores (presumably the one that would have run the waiting task). It may be possible to circumvent this using the avg_ncpus setting but it didn't work for me. Setting this to 1 allowed only one task to be downloaded but after a few seconds, BOINC simply went back and got another. That was a very specific bug - introduced by mistake in v7.6.3 - that Cliff Harding found and we worked through from here. Unless you were seeing similar symptoms in cpu_sched_debug logging - specifically like [cpu_sched_debug] using 2.00 out of 6 CPUs I doubt this change is relevant to you. Work fetch and app_config.xml still aren't hooked up. |
|
7)
Message boards :
News :
Jobs incoming!
(Message 936)
Posted 31 Aug 2015 by Richard Haselgrove Post: "It was a long weekend", "There was a challenge on", "You told us it was broken", ... two machines woken up and told to report for duty. They'll have to fend for themselves while I sleep. |
|
8)
Message boards :
Number crunching :
issue of the day
(Message 801)
Posted 21 Aug 2015 by Richard Haselgrove Post: The machine which was stuck just now is active again (did a VM reset from Oracle, left BOINC running throughout) and seems to be busy (%CPU 86) with Beginning CMSSW wrapper script |
|
9)
Message boards :
Number crunching :
issue of the day
(Message 797)
Posted 21 Aug 2015 by Richard Haselgrove Post: The machine which got stuck activating the fuse module is still stuck at the same place, but a second machine which was running at the time has picked up the new directory structure without any problems. I'll restart the stuck one. |
|
10)
Message boards :
Number crunching :
issue of the day
(Message 790)
Posted 21 Aug 2015 by Richard Haselgrove Post: 20 minutes into a new task, and the console has been stuck at 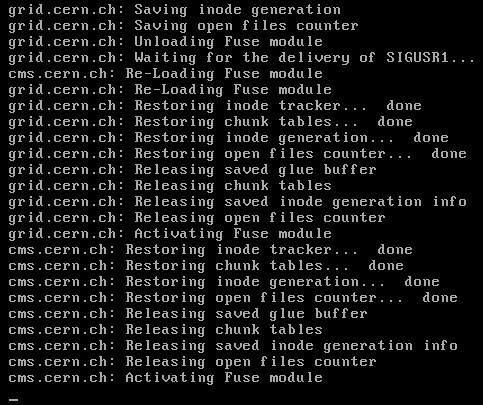 for at least the last 10 of them. Having lit the blue touch paper, I'm now retiring to a safe distance and waiting... |
|
11)
Message boards :
Number crunching :
issue of the day
(Message 786)
Posted 21 Aug 2015 by Richard Haselgrove Post: The machine I was watching yesterday was looping until 22:40, and then switched to the 6-hour cycle at about run-201. It's due to shut down the current BOINC task instance within an hour, and start a new one. It'll be interesting to see how the log map changes. |
|
12)
Message boards :
News :
Agent Fixed
(Message 764)
Posted 20 Aug 2015 by Richard Haselgrove Post: Me too! At least, BoincView has 'gone green' with 100% CPU efficiency. It's after midnight here, so I haven't gone down into the cellar to inspect the console output directly. |
|
13)
Message boards :
News :
Agent Fixed
(Message 749)
Posted 20 Aug 2015 by Richard Haselgrove Post: Doesn't seem to use much CPU (13%). Is that a sign of a problem? I'm running CMS on two machines - an 8-core hyperthreaded i7 with VBox 4.3.26, and a true 4-core i5 with VBox 5.0.2 The older VBox on the i7 is showing similar CPU %ages - mostly 9%-10%, occasional spikes higher. The newer VBox seems to have higher overheads, in the 25%-30% range. I'm using similar monitoring to rbpeake - BoincView. Both programs report CPU usage per core - on a scale up to 100% - so these are all 'low' CPU utilisation, unlike any similar percentages displayed by Task Manager on multi-core machines. All the figures I've given are for today, when the VMs have been essentially idle because of the broken agent. Earlier in the week, when real jobs were running, CPU usage was mostly in the high 90s, and occasionally reached a full 100% (or 1.0000, as BoincView displays the fraction). |
|
14)
Message boards :
News :
Agent Fixed
(Message 748)
Posted 20 Aug 2015 by Richard Haselgrove Post: Yes, run-number logs are being kept now - I'm up to run-5. But the contents seem the same as before. What, in particular, would you like us to watch out for? I'm up to run-57, but they're all very similar, like cron-stderr 20-Aug-2015 17:41 7.1K cron-stdout 20-Aug-2015 17:42 48K glidein-stderr 20-Aug-2015 17:39 38K glidein-stdout 20-Aug-2015 17:39 6.5K I'm waiting for the file sizes to change before I read through another set. Tasks are 'passing through' about once every two minutes, but I don't think I'd say they were 'lasting' that long. Condor lasts for about 5 seconds, and the rest is setup, error, sleep. |
|
15)
Message boards :
News :
Agent Fixed
(Message 741)
Posted 20 Aug 2015 by Richard Haselgrove Post: Yes, run-number logs are being kept now - I'm up to run-5. But the contents seem the same as before. What, in particular, would you like us to watch out for? Edit - that was a reply to Laurence, and a post about additional information being available, now deleted. |
|
16)
Message boards :
News :
Agent Fixed
(Message 738)
Posted 20 Aug 2015 by Richard Haselgrove Post: This one stood out to me: glidein.stderr, line 98 Error parsing command line arguments: Unrecognized option: -dont-verify-ac |
|
17)
Message boards :
News :
Agent Fixed
(Message 734)
Posted 20 Aug 2015 by Richard Haselgrove Post: I saw a glidein.stderr very similar to Yeti's, with the proxy and credential errors - it was quickly deleted. I also captured this: 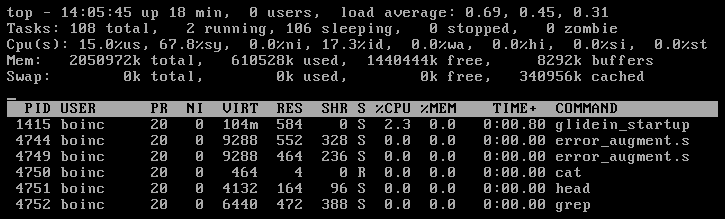 after which, everything exited and went back to sleep. |
|
18)
Message boards :
Number crunching :
Job queue empty!!
(Message 717)
Posted 19 Aug 2015 by Richard Haselgrove Post: Sorry old chap, I don't understand your banter! Sorry, reference to my BoincView network monitoring software. It flags tasks with 'low CPU efficiency' in yellow (among sundry other colour-coded alerts). In the case of CMS, 'low CPU efficiency' correlates to 'low CPU usage', which basically means no CMS jobs running in the VM. At the time I posted, I assumed that simply meant the system had run out of jobs. Then I went upstairs and checked the VM console and logs - and found it possibly meant glitches with the new Agent scripts. See follow-up posts in the News area. |
|
19)
Message boards :
News :
Agent Broken
(Message 709)
Posted 19 Aug 2015 by Richard Haselgrove Post: And mine is 21:01:01 +0100 2015-08-19 [INFO] Starting CMS Application (I think those are the right starting/ending points for the cycle) IDs are right for this project - CP is ID 38, I am 229. |
|
20)
Message boards :
News :
New CMS Agent
(Message 701)
Posted 19 Aug 2015 by Richard Haselgrove Post: Doesn't like me either: /cvmfs/cms.cern.ch/CMS@Home/agent/CMSJobAgent.sh: line 9: export: `Haselgrove ': not a valid identifier |
Next 20

©2024 CERN